Short-Read vs. Long-Read RNA-Seq: A Comprehensive Guide for Biomedical Researchers
This article provides a definitive comparison of short-read and long-read RNA sequencing technologies, tailored for researchers and drug development professionals.
Short-Read vs. Long-Read RNA-Seq: A Comprehensive Guide for Biomedical Researchers
Abstract
This article provides a definitive comparison of short-read and long-read RNA sequencing technologies, tailored for researchers and drug development professionals. It covers the foundational principles of both methods, explores their specific applications in areas like isoform discovery and single-cell analysis, and offers practical guidance for troubleshooting and optimizing sequencing workflows. By synthesizing recent validation studies and comparative data, this guide empowers scientists to select the most appropriate technology and analytical approaches for their specific research goals, from basic discovery to clinical translation.
Understanding the Core Technologies: From Short-Read Accuracy to Long-Read Comprehensiveness
Core Technological Principles
Short-read sequencing (also known as next-generation sequencing) involves fragmenting DNA or RNA into small pieces typically 50-300 base pairs in length before sequencing [1] [2]. These fragments are amplified and sequenced in parallel using platforms such as Illumina, which employs sequencing by synthesis with fluorescently labeled nucleotides, or Ion Torrent, which detects pH changes during nucleotide incorporation [1] [3]. The resulting short reads are then computationally aligned to a reference genome for analysis.
Long-read sequencing, often termed third-generation sequencing, sequences much longer DNA or RNA fragments spanning thousands to hundreds of thousands of base pairs in single, continuous reads [4] [3] [5]. Two main platforms dominate this field: Pacific Biosciences (PacBio) uses Single Molecule Real-Time (SMRT) sequencing where fluorescent nucleotide incorporation is detected in real-time as DNA polymerase synthesizes new strands [4] [5]; Oxford Nanopore Technologies (ONT) measures changes in electrical current as individual DNA or RNA molecules pass through protein nanopores [4] [5].
Table 1: Fundamental Characteristics of Sequencing Technologies
| Feature | Short-Read Sequencing | Long-Read Sequencing |
|---|---|---|
| Read Length | 50-300 base pairs [1] [2] | 1,000-4,000,000+ base pairs [4] [3] |
| Primary Platforms | Illumina, Ion Torrent [1] [2] | PacBio, Oxford Nanopore [4] [5] |
| Key Chemistry | Sequencing by synthesis (Illumina) [1] | SMRT sequencing (PacBio), Nanopore detection (ONT) [4] [5] |
| Base Accuracy | ~99.9% [4] | 95%-99.9% (platform-dependent) [4] |
| Typical Throughput | 65-3,000 Gb per run [4] | Up to 277 Gb (ONT) or 90 Gb (PacBio) per run [4] |
Experimental Workflows and Methodologies
RNA Sequencing Library Preparation
For short-read RNA sequencing, the standard workflow begins with RNA extraction, followed by mRNA enrichment or ribosomal RNA depletion [2]. The RNA is then reverse-transcribed into complementary DNA (cDNA), which is fragmented into short pieces [6] [2]. Adapters are ligated to the fragments for amplification and sequencing on platforms such as Illumina NovaSeq [1] [3].
Long-read RNA sequencing offers multiple library preparation paths. The PCR-amplified cDNA protocol requires minimal input RNA and generates high throughput [6]. For sufficient RNA quantities, amplification-free direct cDNA sequencing avoids PCR biases [6]. Most distinctively, Nanopore's direct RNA sequencing protocol sequences native RNA without reverse transcription or amplification, preserving natural RNA modifications [6] [2].
The SG-NEx Benchmarking Study: Experimental Design
The Singapore Nanopore Expression (SG-NEx) project represents one of the most comprehensive comparisons of RNA sequencing protocols to date [6]. This systematic benchmark profiled seven human cell lines (including HCT116, HepG2, A549, MCF7, K562, HEYA8, and H9 embryonic stem cells) using five different RNA-seq protocols with multiple replicates [6].
The experimental design included:
- Short-read cDNA sequencing (Illumina)
- Nanopore long-read direct RNA sequencing
- Nanopore amplification-free direct cDNA sequencing
- Nanopore PCR-amplified cDNA sequencing
- PacBio IsoSeq [6]
The study incorporated six different spike-in RNA controls with known concentrations (Sequin V1/V2, ERCC, SIRVs E0/E2, and long SIRVs) to enable quantitative accuracy assessment [6]. Additional transcriptome-wide N6-methyladenosine (m6A) profiling allowed evaluation of RNA modification detection capabilities from direct RNA-seq data [6]. In total, the core dataset comprised 139 libraries across 14 cell lines and tissues with an average sequencing depth of 100.7 million long reads for the core cell lines [6].
Performance Comparison and Experimental Data
Quantitative Performance Metrics
Table 2: Performance Comparison Across RNA Sequencing Platforms
| Performance Metric | Short-Read RNA-Seq | PacBio Long-Read | Nanopore Long-Read |
|---|---|---|---|
| Throughput (per run) | 65-3,000 Gb [4] | Up to 90 Gb [4] | Up to 277 Gb [4] |
| Cost per Gb | $12-$27 [4] | $65-$200 [4] | $22-$90 [4] |
| Key Strengths | High accuracy, Cost-effective, Established workflows [1] [2] | High fidelity (HiFi) reads, Excellent for isoform discovery [4] [3] | Direct RNA sequencing, Detection of modifications, Longest reads [6] [4] |
| Primary Limitations | Limited isoform resolution, Mapping challenges in repetitive regions [1] [4] | Lower throughput, Higher cost per sample [4] [2] | Higher error rates, Complex data analysis [4] [5] |
Applications and Strengths Comparison
Short-read RNA-seq excels in applications requiring high accuracy and quantitative precision for differential gene expression analysis [2]. Its high throughput and lower cost make it ideal for large-scale studies involving many samples [1] [3]. However, it struggles with transcript isoform discrimination because short reads cannot unambiguously connect distant exons, leading to challenges in identifying full-length transcript structures [4].
Long-read RNA-seq enables complete transcript sequencing, providing unambiguous information about splice variants, fusion transcripts, and allele-specific expression [4]. The SG-NEx study demonstrated that long-read sequencing more robustly identifies major isoforms compared to short-read approaches [6]. Nanopore's direct RNA sequencing uniquely allows detection of RNA base modifications without additional chemical treatments, enabling epitranscriptome studies alongside transcript expression [6] [2].
In single-cell RNA sequencing comparisons, both methods recover a large proportion of cells and transcripts with high comparability, though platform-specific processing introduces distinct biases [7]. Short-read sequencing provides higher sequencing depth, while long-read sequencing preserves full-length transcript information and enables filtering of artifacts identifiable only from complete transcripts [7].
Research Reagent Solutions
Table 3: Essential Research Reagents and Platforms for RNA Sequencing
| Reagent/Platform | Function | Application Context |
|---|---|---|
| Illumina NovaSeq 6000 | Short-read sequencing platform | High-throughput gene expression studies, large sample cohorts [3] |
| PacBio Sequel IIe | Long-read sequencing with HiFi accuracy | Full-length isoform sequencing, variant detection [4] [3] |
| Oxford Nanopore PromethION | High-throughput nanopore sequencing | Direct RNA sequencing, modification detection [4] |
| 10x Genomics Chromium | Single-cell partitioning system | Single-cell RNA sequencing libraries [7] |
| Spike-in RNA Controls (ERCC, Sequin, SIRVs) | Quantitative standards | Normalization and quality control [6] |
| MAS-ISO-seq Kit (PacBio) | cDNA concatenation for throughput | Enhanced long-read single-cell RNA sequencing [7] |
Analysis Workflows and Computational Tools
Bioinformatics Processing Pipelines
The analysis of short-read RNA-seq data typically involves quality control (FastQC), alignment to a reference genome (STAR, HISAT2), and transcript quantification (featureCounts, HTSeq) [1]. Differential expression analysis is then performed using tools such as DESeq2 or edgeR [4].
Long-read RNA-seq data analysis requires specialized tools to address higher error rates and full-length transcript reconstruction. The SG-NEx project provides a community-curated nf-core pipeline to standardize data processing [6]. Benchmarking studies such as the Long-read RNA-Seq Genome Annotation Assessment Project (LRGASP) have evaluated multiple computational tools, with popular options including StringTie2, FLAMES, ESPRESSO, IsoQuant, and Bambu [4]. These tools output transcript-level count matrices suitable for differential expression analysis with established statistical methods.
Single-Cell Analysis Comparison
In single-cell RNA-seq comparisons, the same 10x Genomics cDNA libraries sequenced with both Illumina short-read and PacBio long-read platforms demonstrate that both methods yield highly comparable gene expression results [7]. However, platform-specific processing introduces distinct biases: short-read sequencing provides higher coverage, while long-read sequencing preserves full-length transcripts and enables identification of sequencing artifacts [7]. PacBio's MAS-ISO-seq (now Kinnex) protocol concatenates multiple transcripts into longer sequencing fragments, significantly improving throughput for single-cell long-read applications [7].
Short-read and long-read RNA sequencing technologies offer complementary strengths for transcriptome analysis. Short-read approaches provide cost-effective, high-accuracy solutions for gene-level expression quantification, while long-read methods deliver unprecedented insights into transcript isoform diversity and RNA modifications. The SG-NEx benchmark demonstrates that long-read sequencing more robustly identifies major isoforms and enables detection of complex transcriptional events [6]. As long-read technologies continue to improve in accuracy and throughput while decreasing costs, they are poised to become foundational tools for exploring transcriptome complexity in basic research and drug development programs. Researchers should select the appropriate technology based on their specific objectives, considering that a hybrid approach often provides the most comprehensive transcriptional profiling.
Next-generation sequencing technologies have become foundational for transcriptome analysis, primarily divided into short-read and long-read approaches. Short-read sequencing (e.g., Illumina) provides high-throughput, cost-effective data ideal for gene-level expression quantification [8]. In contrast, long-read sequencing from PacBio and Oxford Nanopore Technologies (ONT) sequences entire RNA transcripts from end to end, enabling the direct observation of full-length splice variants and isoform diversity without the need for assembly [9]. This capability is transformative for exploring complex biological questions in human disease and basic biology, moving beyond simple gene counting to a complete picture of transcriptome complexity [9].
Technology Platform Comparison
The table below summarizes the core specifications and performance metrics of the three major sequencing platforms.
Table 1: Core Platform Specifications and Performance
| Feature | Illumina | PacBio HiFi | Oxford Nanopore (ONT) |
|---|---|---|---|
| Read Type | Short-read | Highly accurate long-read (HiFi) | Long-read |
| Typical Read Length (RNA-seq) | 50-300 bp [10] | Up to 25 kb [11] | 100 kb+ with ultra-long protocols [8] |
| Single-Read Accuracy | ~99.9% (Q30) [8] | ~99.9% (Q30) [11] | >99% with Q20+ chemistry [12] |
| Key RNA-seq Strengths | Gene expression profiling, counting studies [10] | Full-length isoform sequencing, allele-specific analysis, isoform quantification [13] | Direct RNA sequencing, simultaneous detection of modifications & isoforms [14] |
| Throughput & Cost | High throughput, lowest cost per base [8] | High throughput on Revio; higher cost than Illumina [8] | PromethION enables high throughput; cost decreasing [8] |
| Experimental Data (from cited studies) | High inferential variability in transcript quantification [13] | Strong concordance with Illumina gene counts (Pearson >0.9); more reliable quantification for complex genes [13] | Detects isoforms, poly-A tail length, and RNA modifications (e.g., m6A) simultaneously in a single run [14] |
Experimental Data and Performance Benchmarks
Transcriptome Analysis: Long Reads Reveal Hidden Complexity
A key application of long-read RNA-seq is the discovery and accurate quantification of transcript isoforms. A June 2025 study directly compared PacBio Kinnex (a high-throughput HiFi method) with Illumina short-read sequencing on sample-matched datasets [13]. The research found that while gene-level quantification was strongly concordant (Pearson correlations exceeding 0.9), PacBio Kinnex demonstrated more consistent replicate-to-replicate quantification for complex genes. In contrast, Illumina data showed "substantially higher inferential variability," leading to unreliable quantifications that manifested as "transcript flips across replicates or transcript division of expression among multiple similar transcripts" [13].
Furthermore, long-read technologies are adept at finding novel biology that short reads miss. In a study of human oocytes, PacBio's Iso-Seq method revealed that nearly 40% of the isoforms detected were novel transcripts not present in the standard GENCODE annotation [13]. Similarly, Oxford Nanopore direct RNA sequencing has been used to simultaneously analyze mRNA modifications (such as m6A), splicing patterns, and poly-A tail length in leukemia cells, revealing complex interactions between these regulatory features—something not possible with short-read cDNA sequencing [14].
Variant Calling and Detection of Structural Variants
Long reads are highly effective for calling variants and resolving complex regions of the genome. A preprint from Dana-Farber and Harvard, analyzing 202 human samples with PacBio Kinnex, identified an average of 88 significant allele-specific splicing events per sample, 46% of which involved unannotated junctions [13]. The study also noted that PacBio HiFi data had "significantly higher SNP calling performance" than ONT due to the latter's higher sequencing error rate [13].
However, ONT has made significant progress. A 2025 clinical genetics study reported that a comprehensive ONT sequencing pipeline achieved 100% sensitivity for detecting clinically relevant single nucleotide variants (SNVs) and structural variants (SVs), outperforming short-read sequencing in variant phasing and repeat sizing. The method successfully resolved four clinical cases that had remained ambiguous with short-read data alone [14].
Table 2: Key Experimental Findings from Recent Studies (2024-2025)
| Study Focus | Platform(s) Used | Key Experimental Finding | Implication |
|---|---|---|---|
| Transcript Quantification | PacBio Kinnex vs. Illumina [13] | Pearson correlation of >0.9 at gene level, ~0.9 at transcript level; Illumina showed higher replicate-to-replicate variability. | HiFi long reads provide isoform-resolution data with quantification accuracy matching short reads. |
| Novel Isoform Discovery | PacBio Iso-Seq [13] | ~40% of isoforms detected in human oocytes were novel and unannotated in GENCODE. | Short-read limitations have led to a significant underestimation of transcriptome diversity. |
| Multi-Feature RNA Analysis | ONT Direct RNA Seq [14] | Simultaneously mapped m6A modifications, poly-A tail length, and isoform structures in native RNA from sepsis blood. | Provides a multi-dimensional view of RNA regulation not feasible with indirect cDNA methods. |
| Clinical Variant Detection | ONT [14] | 100% sensitivity for SNVs and SVs in a clinical validation study; resolved previously ambiguous cases. | A single long-read test can replace multiple short-read based assays for comprehensive genetic diagnosis. |
Microbiome and Metagenomic Studies
Long-read sequencing also excels in microbiome profiling by providing full-length 16S rRNA sequencing, which offers superior taxonomic resolution compared to short-read sequencing of hypervariable regions. A 2025 comparative study of soil microbiomes found that both PacBio and ONT produced comparable assessments of bacterial diversity, with PacBio showing a slight edge in detecting low-abundance taxa [15]. The study concluded that, despite differences in raw sequencing accuracy, both long-read platforms enabled clear clustering of samples by soil type, whereas Illumina sequencing of just the V4 region failed to do so (p=0.79) [15].
Experimental Protocols and Workflows
Protocol for Single-Cell Long-Read RNA Sequencing (MAS-ISO-seq/Kinnex)
The following workflow details the method used in a 2025 study to sequence the same 10x Genomics cDNA library on both PacBio and Illumina platforms for a direct comparison [7].
Key Steps Explained:
- Single-Cell Library Preparation: Cells are partitioned into nanoliter-scale Gel Beads-in-emulsion (GEMs) using the 10x Genomics Chromium platform. Within each GEM, reverse transcription occurs using barcoded oligo-dT primers to generate full-length cDNA, where all cDNA from a single cell shares the same cell barcode and unique molecular identifier (UMI) [7].
- Platform-Specific Library Processing (The Critical Divergence):
- For Illumina Sequencing: The full-length cDNA is enzymatically sheared to a target size of 200-300 bp. Standard Illumina sequencing adapters and sample indexes are added via ligation and PCR to create libraries compatible with bridge amplification on the NovaSeq 6000 [7].
- For PacBio Long-Read Sequencing (MAS-ISO-seq/Kinnex): The cDNA is processed to remove template-switching oligo (TSO) artefacts using a biotinylated primer. The cDNA is then segmented with adapters in multiple PCR reactions, and these segments are directionally assembled into long synthetic concatemers called MAS arrays (averaging 10-15 kb). These arrays are then sequenced on a PacBio Sequel IIe or Revio system, and the resulting reads are bioinformatically decomposed back into the original individual transcripts [7].
Protocol for Direct RNA Sequencing with Oxford Nanopore
This workflow is based on studies that used ONT direct RNA sequencing to simultaneously profile RNA modifications, isoforms, and poly-A tail length [14].
Key Steps Explained:
- RNA Preparation: Total RNA is extracted, and poly-adenylated RNA is selected using oligo-dT beads. Notably, the RNA remains in its native state without being converted to cDNA [14].
- Adapter Ligation: Specialized adapters are ligated to the RNA molecules, which facilitate the movement of the RNA through the nanopore.
- Sequencing and Basecalling: The library is loaded onto a flow cell (e.g., R10.4.1). As individual RNA strands are pulled through the protein nanopores by an ionic current, changes in the current are measured in real time. These signal changes are directly decoded by basecalling software (e.g., Dorado) to determine the RNA sequence and simultaneously identify base modifications, without the need for chemical treatment like bisulfite conversion [12] [14].
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 3: Key Reagents and Kits for Featured Experiments
| Item Name | Provider | Function / Application |
|---|---|---|
| Chromium Single Cell 3' Reagent Kits | 10x Genomics | Generates barcoded single-cell full-length cDNA libraries from thousands of individual cells for subsequent sequencing on any platform. Essential for single-cell RNA-seq workflows [7]. |
| MAS-ISO-seq for 10x Genomics Kit (now Kinnex) | Pacific Biosciences | Prepares 10x Genomics cDNA for PacBio sequencing. Removes TSO artefacts and assembles transcripts into long concatemers to dramatically increase throughput for single-cell isoform sequencing [7]. |
| Ligation Sequencing Kit | Oxford Nanopore | The standard kit for preparing DNA libraries for ONT sequencing. Used for a wide variety of applications, including amplicon sequencing (e.g., 16S rRNA) and cDNA sequencing [12]. |
| SMRTbell Prep Kit | Pacific Biosciences | Used to prepare genomic DNA or cDNA libraries for PacBio sequencing by ligating hairpin adapters to create circularizable templates, which is fundamental for generating HiFi reads [11]. |
| Q20+ Chemistry Reagents | Oxford Nanopore | Refers to the latest sequencing chemistry and flow cells (e.g., R10.4.1) that provide a raw read accuracy of >99%, significantly improving data quality for all application areas [12]. |
| Direct RNA Sequencing Kit | Oxford Nanopore | Enables sequencing of native RNA molecules without reverse transcription, allowing for the direct detection of nucleotide modifications alongside sequence information [14]. |
The choice between short-read and long-read RNA sequencing (RNA-seq) technologies is a fundamental decision that directly impacts the scope and resolution of transcriptomic research. Short-read sequencing, predominantly offered by Illumina, has been the workhorse of gene expression studies for over a decade, providing high-throughput, cost-effective data generation. In contrast, long-read technologies from Pacific Biosciences (PacBio) and Oxford Nanopore Technologies (ONT) capture full-length transcripts, enabling comprehensive isoform characterization. This guide provides an objective comparison of these platforms across critical performance metrics—read length, accuracy, throughput, and cost—framed within the context of designing rigorous RNA-seq experiments. By synthesizing current experimental data and technical specifications, we aim to equip researchers with the analytical framework needed to select the optimal sequencing strategy for their specific biological questions.
Performance Metrics Comparison
The fundamental differences between short-read and long-read sequencing technologies manifest directly in their performance specifications, which in turn dictate their appropriate applications. The table below provides a systematic comparison of the current platforms across the four critical performance metrics.
Table 1: Direct comparison of short-read and long-read RNA sequencing platforms across key performance metrics.
| Platform | Typical Read Length | Base Accuracy | Throughput per Flow Cell/SMRT Cell | Estimated Cost per Gb |
|---|---|---|---|---|
| Illumina (Short-Read) | 50-300 bp [16] | ~99.9% [4] [17] | 65-3,000 Gb [4] | $12 - $27 [4] |
| PacBio (Long-Read) | Up to 25 kb [4] | >99.9% (HiFi reads) [4] [17] | Up to 90 Gb [4] | $65 - $200 [4] |
| ONT (Long-Read) | Up to 4 Mb [4] | 95% - 99% (R10.4 chemistry) [4] | Up to 277 Gb [4] | $22 - $90 [4] |
Interpreting the Metrics for Project Design
Read Length and Biological Resolution: Short reads (50-300 bp) are highly effective for quantifying overall gene expression levels and detecting single nucleotide variants [16]. However, their fragmented nature makes the confident assembly of full-length transcript isoforms challenging [4]. Long reads, which can span thousands to millions of bases, capture entire transcripts within a single read, providing unambiguous evidence of splice variants, alternative transcription start sites, and polyadenylation sites [4] [18]. This makes long-read sequencing essential for studies focused on alternative splicing, novel isoform discovery, fusion transcripts, and complex RNA biotypes like circular RNAs [4].
Accuracy and Throughput Considerations: Short-read platforms offer exceptionally high per-base accuracy and the highest overall throughput, making them ideal for applications requiring deep sequencing of many samples, such as large-scale differential gene expression studies [4]. Long-read accuracy varies by technology: PacBio's HiFi reads achieve high accuracy through circular consensus sequencing, while ONT's accuracy has improved significantly with newer chemistries [4] [17]. ONT generally provides higher throughput than PacBio at a lower cost per gigabase, though with generally lower single-read accuracy [4]. A key strategic consideration is that long-read sequencing delivers fewer total reads than short-read platforms, but each read carries vastly more transcriptional information [18].
Cost Analysis and Strategic Deployment: While the cost per gigabase of short-read sequencing is substantially lower (as shown in Table 1), the most cost-effective technology is determined by the biological question rather than the price per base [18]. Short reads remain the most economical choice for gene-level expression quantification, genotyping, and variant calling [16]. For projects where isoform-level resolution is critical, long-read sequencing can provide a greater return on investment by resolving questions that short reads cannot, thereby reducing downstream validation costs and accelerating discovery [18]. A hybrid approach, using short reads for high-depth quantification across many samples and long reads for full-length structure determination on a subset of samples, often offers an optimal balance of cost and biological insight [18].
Experimental Protocols and Benchmarking Studies
Robust benchmarking studies are crucial for understanding the real-world performance of sequencing technologies. Below, we detail the methodologies of key recent experiments that provide comparative data.
Protocol 1: Cross-Platform Comparison of the Same cDNA Library
A 2025 study directly investigated the comparability of data from short- and long-read sequencing by using the same 10x Genomics 3' complementary DNA (cDNA) library, tagged with cell barcodes and unique molecular identifiers (UMIs) [7].
- Sample Preparation: Patient-derived organoid cells of clear cell renal cell carcinoma (ccRCC) were used. Single-cell suspensions were processed on the 10x Genomics Chromium platform using the Single Cell 3' Reagent Kits (v3.1 Chemistry Dual Index) to generate full-length cDNA [7].
- Library Preparation and Sequencing:
- Illumina Short-Read: The cDNA was enzymatically sheared to 200-300 bp, and libraries were constructed with standard Illumina protocols. Sequencing was performed on an Illumina NovaSeq 6000 to achieve ~300,000 reads per cell [7].
- PacBio Long-Read: The same cDNA (45 ng/sample) was used for MAS-ISO-seq (multiplexed array isoform sequencing) library preparation. This protocol involves removing template switching oligo (TSO) artefacts, incorporating segmentation adapters, and directionally assembling cDNA segments into long concatenated arrays (10-15 kb) for efficient sequencing on a PacBio Sequel IIe system [7].
- Data Analysis: A per-molecule comparison was conducted by matching reads through their cell barcode and UMI. Gene count matrices generated from both methods were cross-compared using state-of-the-art bioinformatic pipelines [7].
- Key Finding: Both methods recovered a large proportion of cells and transcripts and showed high comparability. However, platform-specific processing introduced biases; short reads provided higher sequencing depth, while long reads allowed for the retention of short transcripts and filtering of specific artefacts [7].
Protocol 2: The SG-NEx Systematic Multi-Protocol Benchmark
The Singapore Nanopore Expression (SG-NEx) project established a comprehensive benchmark dataset, profiling seven human cell lines with multiple RNA-seq protocols to enable rigorous tool assessment and biological discovery [6].
- Experimental Design: The core study sequenced seven human cell lines (e.g., HCT116, HepG2, A549) with multiple replicates using five different protocols:
- Illumina short-read cDNA sequencing (PE 150-bp).
- Nanopore direct RNA sequencing (native RNA).
- Nanopore amplification-free direct cDNA sequencing.
- Nanopore PCR-amplified cDNA sequencing.
- PacBio IsoSeq [6].
- Spike-in Controls: Sequencing runs included spike-in RNAs with known concentrations (Sequin, ERCC, SIRVs) to provide an absolute reference for evaluating the accuracy of transcript identification and quantification across platforms [6].
- Extended Data and Analysis: The core dataset was extended with additional cell lines and tissues. The project also provides a community-curated nf-core pipeline for standardized data processing. The study compared protocols based on read length, coverage, throughput, and accuracy in transcript expression, demonstrating that long-read sequencing more robustly identifies major isoforms [6].
Protocol 3: Evaluation of Long-Read Sequencing for Isoform Discovery in Human Blood
A 2025 study evaluated PacBio long-read RNA-seq for identifying novel RNA isoforms in human whole blood, with a unique focus on comparing two genome references: GRCh38 and the telomere-to-telomere T2T-CHM13 assembly [19].
- Sample Collection and Library Preparation: Peripheral whole blood was collected from four healthy individuals into PAXgene Blood RNA Tubes. Total RNA was extracted, and cDNA libraries were prepared using the PacBio Iso-Seq Express 2.0 kit. Sequencing was performed on a PacBio Sequel IIe system [19].
- Bioinformatic Processing: Raw PacBio data were processed using the Isoseq v4.0.0 pipeline. The resulting transcripts were aligned to both the GRCh38 and T2T-CHM13 genomes using
pbmm2and classified usingSQANTI3[19]. - Key Finding: The study identified a vast number of novel isoforms in blood, highlighting the power of long-read sequencing for transcriptome annotation. The choice of reference genome significantly impacted results, with GRCh38 identifying more genes and isoforms, while T2T-CHM13 likely offers greater accuracy in repetitive regions [19].
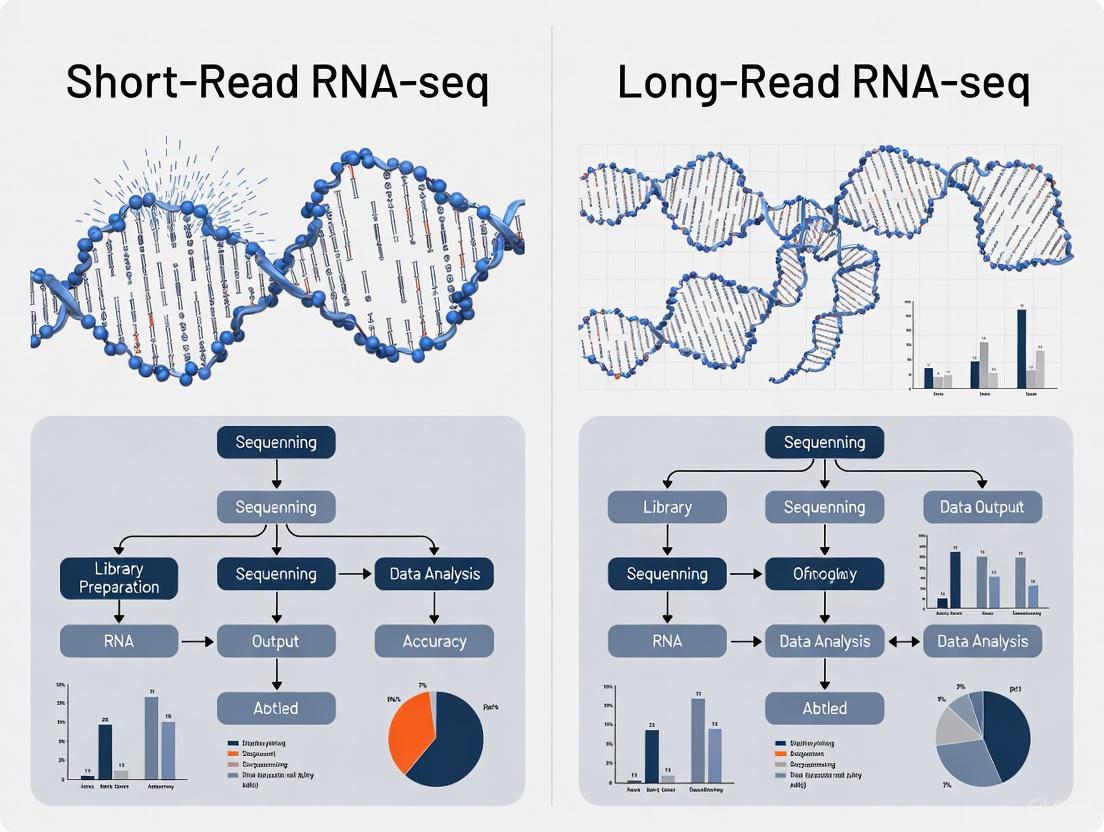
Visualizing Experimental Workflows
The following diagrams illustrate the key experimental workflows and technology principles described in the benchmarking studies.
Core Technology Comparison
core-technologies
Cross-Platform Benchmarking Workflow
benchmarking-workflow
The Scientist's Toolkit: Essential Research Reagents and Materials
Successful execution of a comparative RNA-seq study requires careful selection of reagents and materials. The following table details key solutions used in the featured experiments.
Table 2: Key research reagents and materials used in benchmark RNA-seq experiments.
| Item | Function | Example Product / Kit |
|---|---|---|
| Single-Cell Barcoding Kit | Partitions single cells, labels all cDNA from a cell with the same barcode, and tags individual transcripts with a UMI for digital counting. | 10x Genomics Chromium Single Cell 3' Kit [7] |
| cDNA Synthesis Kit | Generates stable, full-length cDNA from RNA templates for subsequent library preparation. | Component of 10x Genomics 3' Kit [7] |
| Short-Read Library Prep Kit | Prepares fragmented cDNA for Illumina sequencing (end repair, A-tailing, adapter ligation, index PCR). | Illumina TruSeq mRNA Stranded Kit [20] |
| Long-Read Library Prep Kit | Prepares cDNA for PacBio sequencing, often involving concatenation to improve throughput. | PacBio MAS-ISO-seq for 10x Genomics Kit [7] |
| Spike-In RNA Controls | Synthetic RNA molecules added in known quantities to evaluate technical performance, sensitivity, and quantification accuracy. | Sequins, ERCC, SIRVs [6] |
| RNA Extraction Kit | Isolves high-quality, intact total RNA from complex biological samples like whole blood. | PAXgene Blood RNA Kit [19] |
| Bioanalyzer / TapeStation | Provides microfluidic electrophoretic analysis of RNA and DNA library quality, size, and concentration. | Agilent 2100 Bioanalyzer [7] [20] |
Long-read RNA sequencing (lrRNA-seq) has undergone a transformative evolution, emerging from a technology once hampered by significant limitations to become a powerful tool for unraveling transcriptome complexity. While short-read RNA-seq has been the workhorse for gene expression profiling, its fundamental limitation—inability to sequence full-length transcripts—has restricted its capacity to resolve isoform-level biology [4]. The human genome contains approximately 20,000 protein-coding genes but can encode over 300,000 unique protein isoforms through mechanisms like alternative splicing, alternative transcriptional start sites, and alternative polyadenylation [4]. For years, long-read technologies from Pacific Biosciences (PacBio) and Oxford Nanopore Technologies (ONT) promised to overcome short-read limitations but faced substantial hurdles in accuracy and throughput that confined them to niche applications. This guide examines how recent technological advancements have systematically addressed these historical challenges, enabling researchers to leverage long-read sequencing for comprehensive transcriptome analysis.
Historical Limitations and Technical Hurdles
The Accuracy Challenge
Early long-read sequencing platforms were characterized by considerably higher error rates compared to their short-read counterparts. PacBio's single-pass reads initially exhibited random errors with approximately 85-87% accuracy, while ONT technologies showed systematic errors with raw accuracy sometimes below 85% [21]. These error profiles presented significant obstacles for sensitive applications like splice junction identification, variant detection, and confident transcript isoform quantification. The high error rate of nanopore technology was largely due to the inability to control the speed of DNA molecules through the pore, while errors in SMRT sequencing were completely random [17]. This accuracy gap necessitated complex computational correction methods and often required complementary short-read sequencing to validate findings, increasing both cost and analytical complexity.
The Throughput Bottleneck
Throughput limitations presented equally formidable challenges. Early long-read platforms generated orders of magnitude fewer reads than Illumina systems, making transcriptome-wide quantification statistically underpowered and cost-prohibitive for large studies. The modest initial throughput of long-read sequencing technologies meant that the majority of early analytical tools were tested on non-human data or focused on targeted applications [21]. Library preparation was often labor-intensive, and the data processing for organisms with larger genomes was computationally intensive and time-consuming [17]. These limitations restricted long-read RNA-seq to applications where its advantages were absolutely essential, such as de novo transcriptome assembly or resolving complex genomic regions.
Overcoming the Hurdles: Technological Advancements
Revolution in Sequencing Accuracy
The accuracy landscape has dramatically improved through innovations in both biochemistry and computational methods. PacBio's HiFi (High Fidelity) sequencing employs circular consensus sequencing (CCS), where circularized cDNA molecules are sequenced multiple times to derive accurate consensus sequences [4]. This approach generates read accuracy exceeding 99.9% (Q30), rivaling short-read platforms [4] [17]. The number of passes over the same molecule determines final accuracy, with approximately four passes required for Q20 (99% accuracy) and nine passes for Q30 (99.9% accuracy) [21].
ONT has made comparable strides through improved pore chemistry (R10.4) and advanced basecalling algorithms leveraging neural networks. While raw single-pass ONT reads may have a higher error rate than HiFi, consensus accuracy for deep coverage ONT data has improved significantly, with current base-called error rates claimed to be below 5% and continuing to improve [21]. The development of production basecallers like Guppy, along with research versions such as Bonito, has substantially enhanced basecalling performance [21].
Table 1: Evolution of Key Performance Metrics in Long-Read Sequencing
| Parameter | Historical Status (Pre-2018) | Current Status (2024-2025) | Key Advancements |
|---|---|---|---|
| Read Accuracy | 85-90% (PacBio), <85% (ONT) | >99.9% (PacBio HiFi), 95-99% (ONT R10.4) | Circular Consensus Sequencing (PacBio), Improved pore chemistry & neural network basecalling (ONT) |
| Throughput per Run | ~1-5 Gb (PacBio), ~10-20 Gb (ONT PromethION) | Up to 90 Gb (PacBio Revio), Up to 277 Gb (ONT PromethION) | Higher-density flow cells, Improved polymerase longevity (PacBio), Higher pore density (ONT) |
| Typical Read Length | 5-20 kb | 10-25 kb (PacBio), Up to 4 Mb demonstrated (ONT) | Optimized library prep, Polymerase engineering (PacBio), DNA extraction methods (ONT) |
| Cost per Gb | >$1,000 | $65-$200 (PacBio), $22-$90 (ONT) [4] | Platform scaling, Higher multiplexing, Simplified workflows |
| Primary Error Type | Random indels (PacBio), Systematic (ONT) | Greatly reduced indel rate (PacBio), More random error profile (ONT) | Biochemical optimization, Enhanced signal detection |
Figure 1: The Evolution Path of Long-Read Sequencing Technologies
Throughput and Scalability Solutions
Throughput barriers have been shattered through multiple technological approaches. PacBio's MAS-ISO-seq (now relabeled as Kinnex) concatenates full-length transcripts into longer fragments (10-15 kb averages) that can be sequenced more efficiently, with each fragment consisting of an average of 16 transcripts instead of one [7]. This multiplexed approach dramatically increases transcript recovery per sequencing run. The recently released Revio system delivers 15 times more HiFi data than previous platforms, enabling human genomes at scale for less than $1,000 [17].
ONT has achieved remarkable throughput gains through the PromethION platform, which can generate up to 277 Gb per flow cell [4]. This massive throughput increase makes transcriptome-wide studies with deep coverage feasible and cost-effective. Improved library preparation protocols requiring less input RNA and offering faster processing times have further enhanced the practicality of long-read transcriptomics for diverse sample types.
Experimental Validation: Cross-Platform Comparisons
The SG-NEx Comprehensive Benchmark
The Singapore Nanopore Expression (SG-NEx) project conducted a systematic benchmark of long-read RNA sequencing methods across seven human cell lines with multiple replicates [6]. This comprehensive resource compared five different RNA-seq protocols: short-read cDNA, Nanopore direct RNA, amplification-free direct cDNA, PCR-amplified cDNA sequencing, and PacBio IsoSeq. The study incorporated spike-in controls with known concentrations to enable precise accuracy assessment, providing unprecedented insights into protocol performance.
Key findings demonstrated that long-read RNA sequencing more robustly identifies major isoforms compared to short-read approaches [6]. The inclusion of transcriptome-wide N6-methyladenosine (m6A) profiling further illustrated the value of direct RNA sequencing for detecting RNA modifications without additional chemical labeling. This multi-protocol, replicated study design established a new standard for benchmarking long-read technologies and provided the community with an invaluable resource for method development.
LRGASP Consortium Findings
The Long-read RNA-Seq Genome Annotation Assessment Project (LRGASP) Consortium systematically evaluated 14 computational tools using 427 million long RNA-seq reads generated by multiple PacBio and ONT protocols [22]. This large-scale collaborative effort revealed that libraries with longer, more accurate sequences produce more accurate transcripts than those with increased read depth, while greater read depth improved quantification accuracy.
Notably, the consortium found that in well-annotated genomes, tools based on reference sequences demonstrated the best performance, though moderate agreement among bioinformatics tools highlighted variations in analytical goals [22]. The project validated many lowly expressed, single-sample transcripts, suggesting further exploration of long-read data for reference transcriptome creation. This benchmarking effort provided crucial guidance for tool selection and experimental design in long-read transcriptomics.
Table 2: Performance Comparison of RNA Sequencing Technologies
| Sequencing Aspect | Short-Read (Illumina) | PacBio Long-Read | ONT Long-Read |
|---|---|---|---|
| Read Length | 50-300 bp [4] | Up to 25 kb [4] | Up to 4 Mb demonstrated [4] |
| Base Accuracy | 99.9% [4] | 99.9% (HiFi) [4] | 95-99% (R10.4 chemistry) [4] |
| Throughput | 65-3,000 Gb per flow cell [4] | Up to 90 Gb per SMRT cell [4] | Up to 277 Gb per PromethION flow cell [4] |
| Isoform Resolution | Limited (inference required) | Full-length | Full-length |
| RNA Modification Detection | Requires specialized protocols | Limited | Direct detection (native RNA) |
| Primary Applications | Gene expression quantification, Differential expression | Isoform discovery, Fusion detection, Alternative splicing | Isoform discovery, RNA modification, Real-time analysis |
| Cost per Gb | $12-$27 [4] | $65-$200 [4] | $22-$90 [4] |
Advanced Applications Enabled by Modern Long-Read Technologies
Comprehensive Transcriptome Characterization
Contemporary long-read platforms excel at uncovering previously inaccessible aspects of transcriptome biology. Full-length transcript sequencing has revealed extensive alternative splicing patterns, including complex arrangements of exons and introns that were incompletely reconstructed from short-read data [6]. The ability to sequence complete transcripts from end to end has proven particularly valuable for detecting fusion transcripts in cancer, characterizing non-coding RNAs, and identifying novel genes in understudied genomes.
The SG-NEx project demonstrated that long-read sequencing facilitates analysis of full-length fusion transcripts, alternative isoforms, and RNA modifications from the same dataset [6]. This multi-faceted analytical capacity provides a more comprehensive view of transcriptional regulation than was previously possible with short-read approaches alone.
Single-Cell Isoform Resolution
Single-cell RNA sequencing has benefited tremendously from long-read advancements. A 2025 study comparing single-cell long-read and short-read sequencing found that both methods render highly comparable results and recover a large proportion of cells and transcripts when applied to the same 10x Genomics 3′ complementary DNA [7]. However, long-read sequencing provided unique advantages including retention of transcripts shorter than 500 bp and removal of degraded cDNA contaminated by template switching oligos.
The ability to profile isoform expression at single-cell resolution reveals cell-type-specific splicing patterns and regulatory heterogeneity within seemingly homogeneous cell populations [7]. This application is particularly powerful in developmental biology and cancer research, where cellular decision-making often involves isoform switching rather than complete gene activation or silencing.
The Scientist's Toolkit: Essential Research Reagents and Platforms
Table 3: Key Research Reagent Solutions for Long-Read RNA Sequencing
| Reagent/Platform | Function | Key Features | Representative Use Cases |
|---|---|---|---|
| PacBio Kinnex (formerly MAS-ISO-seq) | Transcript multiplexing | Concatenates transcripts into longer fragments (10-15 kb averages) | Increases throughput 16-fold; ideal for transcriptome-wide studies [7] |
| 10x Genomics Single Cell 3' Reagent Kits | Single-cell cDNA synthesis | Partitions cells into GEMs with cell barcodes and UMIs | Single-cell isoform expression profiling [7] |
| ONT Direct RNA Sequencing Kit | Native RNA sequencing | Sequences RNA directly without cDNA conversion | Detection of RNA modifications; avoids reverse transcription bias [6] |
| Spike-in RNA Variants (SIRVs) | Quality control | Synthetic RNA controls with known sequences | Protocol benchmarking; quantification accuracy assessment [6] |
| PacBio SMRTbell Prep Kit | Library preparation for HiFi sequencing | Creates circular templates for CCS | High-accuracy isoform sequencing; variant detection [4] |
| SQANTI3 | Quality control and classification | Comprehensive characterization of transcript models | QC for transcriptome assemblies; isoform classification [7] |
Experimental Design Considerations
Protocol Selection Guidelines
Choosing the appropriate long-read RNA sequencing protocol depends on research goals, sample type, and available resources. For applications requiring the highest accuracy for variant detection or quantitative analysis, PacBio HiFi sequencing is recommended. When detecting RNA modifications or minimizing amplification bias is prioritized, ONT direct RNA sequencing offers unique advantages. For maximum throughput in transcriptome characterization, PCR-amplified cDNA protocols on either platform provide the deepest coverage.
The LRGASP consortium findings suggest that incorporating additional orthogonal data and replicate samples is advised when aiming to detect rare and novel transcripts or using reference-free approaches [22]. For well-annotated genomes, reference-based tools generally outperform de novo methods, though the latter remain valuable for discovering novel transcription events.
Sample Preparation Methodologies
Critical to successful long-read RNA sequencing is appropriate sample handling and library preparation. The MAS-ISO-seq protocol includes a specific step to remove template switching oligo (TSO) contaminants generated during 10x Genomics cDNA synthesis, using a modified PCR primer to incorporate a biotin tag into desired cDNA products followed by capture with streptavidin-coated beads [7]. This refinement significantly improves data quality by eliminating artefacts that can confound analysis.
For native RNA sequencing with ONT platforms, maintaining RNA integrity is paramount. The SG-NEx project optimized protocols for amplification-free direct cDNA sequencing, which requires sufficient input RNA but provides the most direct view of the transcriptome without reverse transcription or PCR biases [6]. These methodological refinements represent the maturation of long-read protocols from proof-of-concept to robust, production-ready workflows.
Figure 2: Experimental Workflow Decision Guide for Long-Read RNA Sequencing
Long-read RNA sequencing has unequivocally overcome its historical hurdles of accuracy and throughput to become a foundational technology for transcriptome analysis. Through circular consensus sequencing, improved chemistries, and advanced basecalling algorithms, accuracy now rivals short-read platforms while maintaining the distinctive advantage of full-length transcript coverage. Throughput limitations have been addressed via multiplexing strategies and platform scaling, making comprehensive transcriptome studies feasible and increasingly cost-effective.
The technology's maturation is evidenced by comprehensive benchmarking efforts like SG-NEx and LRGASP, which provide robust frameworks for experimental design and tool selection [6] [22]. As long-read sequencing continues to evolve toward even higher accuracy, longer reads, and lower costs, its integration with single-cell technologies, spatial transcriptomics, and multi-omics approaches will further expand its transformative potential for understanding transcriptome complexity in health and disease.
Choosing Your Tool: Application-Oriented Strategies for Gene Expression and Isoform Analysis
In the evolving landscape of transcriptomics, both short-read and long-read RNA sequencing technologies offer distinct advantages tailored to specific research goals. While long-read sequencing excels at isoform discovery and full-length transcript characterization, short-read sequencing remains the gold standard for numerous applications requiring high-throughput, accuracy, and cost-efficiency. This guide objectively compares the performance of short-read and long-read technologies, focusing on the established strengths of short-read sequencing for differential gene expression analysis, single nucleotide polymorphism (SNP) detection, and large-scale profiling studies.
Performance Comparison: Short-Read vs. Long-Read RNA Sequencing
The table below summarizes key performance metrics for short-read and long-read RNA sequencing technologies, highlighting their respective advantages in different applications.
Table 1: Performance Comparison of RNA Sequencing Technologies
| Feature | Illumina Short-Read RNA-seq | PacBio Long-Read RNA-seq | ONT Long-Read RNA-seq |
|---|---|---|---|
| Read Length | 50-300 bp [4] | Up to 25 kb [4] | Up to 4 Mb [4] |
| Base Accuracy | >99.9% [4] | ~99.9% (HiFi) [4] [23] | 95%-99% [4] |
| Typical Throughput | 65-3,000 Gb per flow cell [4] | Up to 90 Gb per SMRT cell [4] | Up to 277 Gb per PromethION flow cell [4] |
| Differential Gene Expression | High correlation with qPCR, high reproducibility [6] [24] [13] | High gene-level correlation with Illumina [7] [13] | Robust for major isoforms [6] |
| SNP Detection | High accuracy for SNV calling [23] | High SNP calling performance [13] [23] | More challenging due to higher error rate [13] |
| Isoform Resolution | Limited; requires inference [4] | Excellent for full-length isoforms [4] [25] | Excellent for full-length isoforms [6] |
| Typical Cost per Gb | $12-$27 [4] | $65-$200 [4] | $22-$90 [4] |
Key Applications and Experimental Support
Differential Gene Expression
Short-read RNA sequencing is the established benchmark for quantitative gene expression analysis due to its high throughput, accuracy, and reproducibility.
High Concordance with Orthogonal Methods: In a foundational study comparing short-read sequencing to two-channel microarrays and quantitative PCR (qPCR), neither technology was "decisively better" at measuring differential gene expression. The log2 ratios of gene expression were highly correlated (R = 0.75) between microarrays and sequencing data [24]. This demonstrates the robust quantitative capability of short-read sequencing.
Superior Reproducibility for Complex Genes: A recent large-scale benchmarking study comparing PacBio Kinnex long-read sequencing to Illumina short-reads found that "PacBio and Illumina quantifications were strongly concordant" at the gene level, with Pearson correlations exceeding 0.9 [13]. However, the study also noted that "Illumina exhibited substantially higher inferential variability compared to Kinnex," meaning short-reads showed greater replicate-to-replicate fluctuations for transcript-level quantification. This instability impacted downstream analyses, particularly for complex genes with multiple similar isoforms, where short-reads led to "unreliable quantifications... manifested either as transcript flips across replicates or transcript division of expression among multiple similar transcripts" [13]. This evidence underscores that for standard differential gene (not isoform) expression, short-reads remain highly reliable and reproducible.
SNP and Small Variant Detection
The high base accuracy of short-read sequencing makes it a trusted choice for identifying single nucleotide variants (SNVs) and small insertions/deletions (indels).
Established High Accuracy: Short-read sequencing platforms consistently deliver base accuracies exceeding 99.9% [4]. This low error rate is critical for confidently calling SNPs, which are single-base changes.
Limitations of Long-Read Technologies: While PacBio's HiFi reads also achieve high accuracy, other long-read technologies face challenges. Oxford Nanopore Technologies (ONT) has a higher raw read error rate, which makes "Nanopore SNP calling more challenging" [13]. A preprint cited by PacBio noted that HiFi sequencing detected "~3x more true positives (TP)" for SNP calling than ONT [13]. Furthermore, nanopore sequencing can struggle with "persistent indel errors" [23], a weakness not shared by short-read platforms. For researchers requiring confident SNP and small variant discovery from RNA-seq data, short-read sequencing provides a dependable solution.
High-Throughput Profiling
For large-scale screening studies, such as those in drug discovery, the combination of low per-sample cost and high quantitative accuracy makes short-read sequencing the preferred and most practical option.
Cost-Effectiveness and Scalability: As shown in Table 1, the cost per gigabase for short-read sequencing is significantly lower than that of long-read technologies [4]. This cost advantage is compounded in high-throughput workflows. Specialized short-read protocols like High-Throughput Gene Expression (HT-GEx) screening are designed for projects requiring the processing of hundreds of samples, such as compound or CRISPR treatment phenotyping [26]. These methods work directly from cell lysate and require only 1-2 million reads per sample, making them vastly more economical than standard RNA-seq or Iso-Seq for large-scale projects [26].
Optimized for Gene-Level Analysis: The primary goal of many screening campaigns is to identify genes that are differentially expressed under different conditions (e.g., drug treatments). For this objective, the full-length transcript information provided by long-reads is often unnecessary. Short-read sequencing delivers the high-quality, gene-level expression data required for phenotypic profiling at a scale and cost that is currently unattainable with long-read technologies [26].
Essential Research Reagent Solutions
The table below lists key reagents and materials used in a typical short-read RNA-seq workflow for gene expression studies.
Table 2: Key Research Reagents for Short-Read RNA-seq Workflows
| Reagent/Material | Function | Example Use Case |
|---|---|---|
| Oligo-dT Primers | Selects for polyadenylated mRNA during cDNA synthesis. | Standard mRNA sequencing for eukaryotic cells [7] [24]. |
| Poly(A) Selection Beads | Enriches mRNA from total RNA by binding poly-A tails. | Library preparation for Illumina sequencing [26]. |
| rRNA Depletion Probes | Removes abundant ribosomal RNA to increase coverage of mRNA. | Sequencing of bacterial RNA or degraded samples (e.g., FFPE) [24]. |
| Unique Molecular Identifiers (UMIs) | Tags individual mRNA molecules to correct for PCR amplification bias. | Accurate digital counting of transcripts in single-cell or low-input RNA-seq [7] [26]. |
| SPRI Beads | Performs size selection and clean-up of cDNA and final libraries. | Post-amplification clean-up in Illumina library prep [7]. |
Experimental Workflow Diagram
The following diagram illustrates a typical workflow for differential gene expression analysis using short-read sequencing, from sample preparation to data interpretation.
Short-read RNA sequencing remains an indispensable tool in the modern transcriptomics toolkit. Its high quantitative accuracy, proven reliability for SNP detection, and unparalleled cost-efficiency for profiling large sample cohorts solidify its role in applications where gene-level expression is the primary endpoint. While long-read technologies provide transformative insights into isoform diversity, the ideal use cases for short-reads—differential gene expression, SNP detection, and high-throughput profiling—continue to be foundational for research and drug development.
The eukaryotic transcriptome is a landscape of remarkable complexity, where a single gene can produce multiple distinct RNA transcripts, or isoforms, through mechanisms such as alternative splicing, alternative promoter usage, and alternative polyadenylation. These isoforms can encode proteins with different functions or localization, and their misregulation is increasingly recognized as a hallmark of various human diseases, including cancer and neurological disorders [9]. For decades, short-read RNA sequencing (RNA-seq) has been the cornerstone of transcriptome analysis, offering high-throughput and cost-effective gene expression quantification. However, its fundamental limitation—sequencing RNA in fragmented pieces of 100-200 base pairs—has forced researchers to infer transcript structures computationally, often with ambiguity and inaccuracy [27]. This inability to directly observe full-length transcripts has been a significant bottleneck in fully understanding gene regulation and cellular diversity.
Long-read RNA sequencing technologies, pioneered by PacBio and Oxford Nanopore Technologies (ONT), have emerged as a transformative solution. By sequencing individual RNA molecules from end to end, these technologies provide a direct window into the complete structure of transcripts, effectively moving isoform analysis from a realm of computational inference to one of empirical observation [9] [27]. This capability is critically important for drug development, where understanding the precise molecular mechanisms of disease, discovering novel therapeutic targets like gene fusions, and characterizing biomarker diversity all depend on accurate, isoform-resolved data. This guide provides an objective comparison of the performance of long-read and short-read RNA-seq methodologies, focusing on their capabilities for transcript isoform discovery and quantification, supported by recent experimental data and benchmarking studies.
Technology Comparison: Short-Read vs. Long-Read RNA-Seq
The core difference between these platforms lies in their approach to sequencing. Short-read technologies (e.g., Illumina, Element Biosciences, MGI) sequence by synthesis or ligation, breaking RNA molecules into small fragments that are amplified and sequenced in parallel [17]. In contrast, long-read technologies sequence single molecules without the need for fragmentation.
Pacific Biosciences (PacBio) employs Single Molecule Real-Time (SMRT) sequencing. Its HiFi (High Fidelity) technology, available on platforms like the Revio system, works by repeatedly sequencing a circularized DNA template, generating a consensus read with accuracy exceeding 99.9% [27] [17]. This combines long read lengths (typically 10-20 kb) with high accuracy.
Oxford Nanopore Technologies (ONT) measures changes in an electrical current as an RNA molecule or its cDNA counterpart is threaded through a protein nanopore. This allows for extremely long reads (theoretically up to millions of bases) and direct RNA sequencing without conversion to cDNA, which also enables the detection of RNA modifications [6] [17]. While historically associated with higher error rates, improvements in chemistry (e.g., R10.4 flow cells) and base-calling algorithms have significantly enhanced its accuracy [28] [17].
Table 1: Fundamental Characteristics of RNA Sequencing Technologies
| Feature | Short-Read (e.g., Illumina) | PacBio Long-Read (HiFi) | ONT Long-Read |
|---|---|---|---|
| Typical Read Length | 100-200 bp | 10,000-20,000 bp | 1,000 -> 1,000,000+ bp |
| Primary Sequencing Method | Sequencing by synthesis (ensemble) | Single Molecule Real-Time (SMRT) | Nanopore sensing (single molecule) |
| Key Library Types | cDNA (3’, 5’, or full-length) | Iso-Seq (full-length cDNA) | Direct RNA, direct cDNA, PCR-cDNA |
| Accuracy | High (>99.9%) | Very High (>99.9%) | Varies; lower single-pass, high consensus |
| Isoform Resolution | Indirect (requires assembly) | Direct (full-length observation) | Direct (full-length observation) |
Performance Benchmarking: Discovery and Quantification
Large-scale consortium efforts like the Long-Read RNA-Seq Genome Annotation Assessment Project (LRGASP) have systematically evaluated the performance of these technologies. A key finding is that while short-read sequencing provides greater depth, libraries with longer, more accurate sequences produce more accurate transcript models [22]. Furthermore, the Singapore Nanopore Expression (SG-NEx) project, which profiled seven human cell lines with multiple protocols, reported that "long-read RNA sequencing more robustly identifies major isoforms" compared to short-read methods [6].
Transcript Isoform Discovery
The power of long-read sequencing to discover novel isoforms is one of its most significant advantages. A study profiling human whole blood using PacBio long-read RNA-seq identified approximately 90,000 novel isoforms that were not present in standard reference annotations when using the GRCh38 genome [19]. This demonstrates the vast, uncharted territory of the transcriptome that is accessible with long-read but not short-read technologies.
For the critical task of reconstructing these full-length transcripts from long-read data, specialized bioinformatic tools are essential. A benchmark study comparing several such tools highlighted IsoQuant as a top performer. On simulated Oxford Nanopore data, IsoQuant demonstrated a significantly lower false-positive rate for novel isoform discovery—at least fivefold lower than tools like TALON, FLAIR, and StringTie—while maintaining high sensitivity [28]. This high precision is crucial for ensuring that newly discovered transcripts are biologically real and not computational artefacts.
Transcript Isoform Quantification
Accurately quantifying the abundance of each transcript isoform is as important as discovering them. Short-read tools struggle with this because reads cannot be uniquely assigned to one of several highly similar isoforms from the same gene locus. Long reads, by spanning multiple exons or the entire transcript, resolve this ambiguity.
Specialized computational methods have been developed to handle the unique characteristics of long-read data, such as its higher error rate and coverage biases. LIQA is one such tool that incorporates base quality scores and models read length bias to improve quantification accuracy. In a simulation study, LIQA showed higher correlation with ground-truth isoform expression levels compared to other long-read specific methods like FLAIR and TALON, particularly at lower sequencing depths [29].
Table 2: Performance Summary from Key Benchmarking Studies
| Study / Metric | Technology / Tool | Key Finding | Experimental Context |
|---|---|---|---|
| LRGASP Consortium [22] | Long-read vs. Short-read | Longer, more accurate reads produce more accurate transcripts than increased short-read depth. | Human and mouse stem cell lines; multiple protocols and tools. |
| SG-NEx Project [6] | Long-read RNA-seq | More robustly identifies major isoforms compared to short-read sequencing. | Seven human cell lines; five different RNA-seq protocols. |
| IsoQuant Benchmark [28] | IsoQuant vs. other tools | ≥5x lower false-positive rate for novel transcripts on ONT data. | Simulated and real human ONT cDNA, dRNA, and PacBio data. |
| LIQA Benchmark [29] | LIQA vs. other tools | Higher Spearman’s correlation with true isoform expression at low sequencing depth. | Simulated ONT data with known ground truth. |
| Whole Blood Study [19] | PacBio Long-read RNA-seq | Identified ~90,000 novel transcript isoforms in human whole blood. | Blood from four healthy individuals; PacBio Sequel IIe. |
Experimental Protocols for Isoform Analysis
PacBio Iso-Seq Workflow for Full-Length Transcript Sequencing
A typical Iso-Seq protocol, as used in recent studies [7] [19], involves the following key steps:
- RNA Extraction & QC: High-quality, intact total RNA is extracted (e.g., using PAXgene Blood RNA Kit for blood samples [19]). RNA Integrity Number (RIN) ≥7 is often recommended.
- cDNA Synthesis & Amplification: Full-length cDNA is synthesized from the RNA template using the Iso-Seq Express 2.0 kit. This step incorporates a switch oligo to template-switch at the 5' end of the mRNA and uses an oligo-dT primer to bind the poly-A tail, ensuring synthesis of the complete transcript from the 3' to the 5' end.
- Library Preparation (SMRTbell Construction): The amplified cDNA is repaired, and SMRTbell adapters are ligated to both ends using the SMRTbell prep kit 3.0. This creates a circularizable library molecule essential for the HiFi sequencing process.
- Sequencing: The library is sequenced on a PacBio Sequel IIe or Revio system. On the Revio, the combination of HiFi reads and the MAS-ISO-seq (Kinnex) protocol, which concatenates multiple transcripts, dramatically increases throughput and reduces cost [7] [27] [17].
- Data Processing: Raw data is processed using the SMRT Link software suite or the command-line Isoseq (v4.0.0) tool to generate circular consensus sequences (CCS), identify full-length reads, and cluster them into transcript isoforms.
The following diagram illustrates this workflow and the subsequent computational analysis:
Computational Analysis Pipeline
After generating raw sequencing data, a standard bioinformatic pipeline is employed:
- Read Alignment: Processed reads (CCS for PacBio, base-called reads for ONT) are aligned to a reference genome (e.g., GRCh38 or T2T-CHM13) using spliced aligners like
minimap2orpbmm2[19]. - Isoform Identification & Classification: Tools like Isoseq or FLAIR collapse aligned reads into non-redundant transcript models. These models are then classified against a reference annotation (e.g., from GENCODE) using tools like SQANTI3 [7] [19]. SQANTI3 categorizes transcripts as Full Splice Match (FSM), Incomplete Splice Match (ISM), Novel in Catalog (NIC), or Novel Not in Catalog (NNC), and performs extensive quality control.
- Isoform Quantification: Expression levels of the identified isoforms are quantified. This can be done by counting the number of full-length reads per isoform or using more sophisticated tools like LIQA [29] or IsoQuant [28], which account for sequencing errors and biases.
- Differential Expression & Splicing Analysis: Finally, specialized packages are used to identify statistically significant differences in isoform usage or expression between sample conditions.
The Scientist's Toolkit: Essential Reagents and Computational Solutions
Successful long-read transcriptomic studies rely on a combination of wet-lab reagents and dry-lab computational tools.
Table 3: Key Reagents and Computational Tools for Long-Read Isoform Analysis
| Item | Type | Function / Application |
|---|---|---|
| PacBio Iso-Seq Express 2.0 Kit | Wet-Lab Reagent | Provides reagents for reverse transcription and PCR amplification to generate full-length cDNA for Iso-Seq libraries. |
| PacBio SMRTbell Prep Kit 3.0 | Wet-Lab Reagent | Used to repair DNA and ligate SMRTbell adapters to cDNA, creating the sequencing library. |
| MAS-ISO-seq for 10x Genomics (Kinnex) | Wet-Lab Reagent | Protocol to concatenate transcripts, significantly increasing throughput on PacBio systems for single-cell studies [7]. |
| Oxford Nanopore Direct cDNA or Direct RNA Kit | Wet-Lab Reagent | Library preparation kits for generating sequencing-ready libraries from RNA/cDNA without amplification (direct cDNA) or for sequencing native RNA (direct RNA). |
| IsoQuant | Computational Tool | Accurate reference-based and annotation-free transcript discovery; known for high precision and low false-positive rates [28]. |
| SQANTI3 | Computational Tool | Comprehensive quality control, classification, and curation of long-read transcripts against a reference annotation [7] [19]. |
| LIQA | Computational Tool | Quantifies isoform expression from long-read data, accounting for read-specific quality scores and coverage biases [29]. |
| T2T-CHM13 Genome | Computational Resource | A complete, telomere-to-telomere human genome reference that can improve mapping and annotation in repetitive regions compared to GRCh38 [19]. |
The evidence from recent, rigorous benchmarking studies is clear: long-read RNA sequencing is a powerful and often superior technology for the discovery and quantification of full-length transcript isoforms. It overcomes the fundamental limitations of short-read sequencing by providing direct evidence of transcript structure, thereby eliminating the ambiguity of assembly. This capability is revealing a previously unappreciated depth of transcriptome diversity, with studies routinely identifying tens of thousands of novel isoforms [19]. For researchers and drug development professionals, the adoption of long-read technologies, coupled with robust experimental protocols and specialized computational tools like IsoQuant and LIQA, enables a more precise understanding of disease mechanisms, accelerates the discovery of isoform-based biomarkers and therapeutic targets such as gene fusions, and ultimately paves the way for more targeted and effective therapies. While factors like cost and data processing complexity remain considerations, the continued evolution of platforms like PacBio Revio and ONT, along with their growing adoption in large-scale consortia, signals that long-read RNA-seq is rapidly becoming an indispensable tool for modern transcriptomics.
The comprehensive analysis of complex genomic regions represents a significant challenge in modern genomics, with important implications for understanding genetic diversity, disease mechanisms, and developmental biology. Structural variants (SVs), repetitive sequences, and gene fusions contribute substantially to genomic variation but have proven difficult to characterize accurately using conventional short-read sequencing technologies. These complex regions include repetitive elements, segmental duplications, and structurally dynamic areas that confound alignment and assembly algorithms designed for short DNA fragments [30] [31]. The limitations are particularly pronounced for variants that exceed read lengths or occur in regions with low sequence complexity, leading to gaps in our understanding of genomic architecture and its functional consequences.
The emergence of long-read sequencing technologies has revolutionized our approach to these challenging regions. This comparison guide provides an objective evaluation of short-read and long-read sequencing methodologies for resolving complex genomic features, drawing on recent benchmarking studies and experimental data. We focus specifically on performance metrics including detection sensitivity, variant precision, and breakpoint resolution for different variant types across genomic contexts. By synthesizing evidence from multiple comparative analyses, this guide aims to inform researchers, scientists, and drug development professionals in selecting appropriate methodologies for their specific genomic investigations.
Technological Platforms and Experimental Considerations
Sequencing Technologies and Their Characteristics
Current sequencing approaches for complex genomic regions primarily utilize either short-read (Illumina) or long-read (PacBio and Oxford Nanopore) technologies. Short-read sequencing generates high-quality reads typically ranging from 150-300 bp, while modern long-read technologies produce reads that can span tens of kilobases, with PacBio HiFi reads offering accuracies exceeding 99.9% [32] [33]. The technological differences extend beyond read length to include distinct library preparation methods, error profiles, and throughput considerations that influence their application to complex genomic regions.
Experimental design for SV detection requires careful consideration of sequencing coverage, DNA quality, and analysis pipelines. For short-read SV detection, most algorithms rely on indirect signals such as split reads, discordant read pairs, read depth, and local assemblies rather than direct spanning of complete variants [32] [34]. Long-read approaches benefit from the ability to directly span repetitive regions and large variants, simplifying detection algorithms and enabling more precise breakpoint resolution. Recent benchmarking studies typically utilize 30-60x coverage for comprehensive variant detection, though optimal depth varies by variant type and genomic context [32] [34].
Analysis Pipelines and Software Tools
Specialized computational tools have been developed to leverage the distinct characteristics of each sequencing technology. For short-read data, popular SV callers include Manta, Delly, and Lumpy, which employ combinatorial approaches to detect variant signals [34]. Long-read analysis typically utilizes tools such as Sniffles, cuteSV, and pbsv that leverage continuous alignments across breakpoints [32] [34]. For repetitive elements like short tandem repeats (STRs), tools including HipSTR, GangSTR, and ExpansionHunter are available for both technologies, with performance varying significantly by repeat length and genomic context [35].
The selection of analysis pipelines significantly influences variant detection performance. Studies have demonstrated that variant detection algorithms often have a greater impact on results than the sequencing technologies themselves, emphasizing the importance of appropriate tool selection and parameter optimization [32]. Recent benchmarking efforts have evaluated numerous algorithms across different variant types and genomic contexts to guide these selections.
Table 1: Key Software Tools for Analyzing Complex Genomic Regions
| Genomic Feature | Short-Read Tools | Long-Read Tools | Technology-Agnostic Tools |
|---|---|---|---|
| Structural Variants | Manta, Delly, Lumpy, GridSS | Sniffles, cuteSV, pbsv | SURVIVOR, Jasmine |
| Repetitive Elements | HipSTR, STRetch | TRiCoLoR, STRique | RepeatProfiler, ExpansionHunter |
| Gene Fusions | Factera, GeneFuse, JuLI | - | FindDNAFusion (multi-tool pipeline) |
| Copy Number Variants | CNVnator, Canvas | - | - |
Performance Comparison Across Genomic Contexts
Structural Variant Detection
Structural variants (SVs), defined as genomic alterations ≥50 base pairs, encompass diverse types including deletions, duplications, insertions, inversions, and translocations [30] [33]. These variants represent a major source of genetic variation and disease susceptibility but have proven challenging to detect comprehensively with short-read technologies.
Recent comparative evaluations demonstrate distinct performance patterns between sequencing approaches. A comprehensive benchmark of 11 SV callers using whole-genome sequencing data revealed that short-read-based algorithms generally detect deletions more effectively than other SV types, with Manta showing the highest F1 score (approximately 0.5) for deletions [34]. However, performance substantially declines for duplications, inversions, and insertions, with most short-read callers achieving F1 scores below 0.2 for these variant types [34]. The recall of SV detection with short-read-based algorithms was significantly lower in repetitive regions, especially for small- to intermediate-sized SVs, than that detected with long-read-based algorithms [32].
Long-read sequencing technologies address several of these limitations by enabling direct variant spanning. PacBio HiFi long reads have been shown to identify more de novo indels and SVs with greater accuracy than short reads, with particular advantages in complex regions [32] [33]. For insertion detection specifically, one study found that short-read callers struggled significantly, with most achieving F1 scores close to zero, while long-read approaches demonstrated substantially improved performance [34]. This performance gap is particularly pronounced for insertions larger than 10 base pairs, which are poorly detected by short-read-based algorithms [32].
Table 2: Performance Comparison for Structural Variant Detection
| Variant Type | Short-Read Performance | Long-Read Performance | Key Observations |
|---|---|---|---|
| Deletions | Moderate (F1: ~0.5 with best tools) | High (F1: >0.8) | Short-read performance adequate in non-repetitive regions |
| Insertions | Poor (F1: ~0.1 with best tools) | High | Short-read tools struggle with insertions >10 bp |
| Duplications | Low (F1: <0.2) | Moderate to High | Copy-number based tools (CNVnator, Canvas) perform better for duplications |
| Inversions | Low (F1: <0.2) | Moderate | Challenging for both technologies, but long-reads superior |
| Complex SVs | Limited detection | High resolution | Long-reads enable characterization of complex rearrangements |
Repetitive Sequence Analysis
Repetitive elements pose particular challenges for genomic analysis due to their abundance and sequence similarity. These regions include tandem repeats, transposable elements, and segmental duplications that collectively comprise approximately 3% of the human genome [31] [35]. The high mutation rate of short tandem repeats (STRs)—approximately 2×10⁻³ per locus per generation compared to 10⁻⁸ for single nucleotide variants—makes them particularly dynamic and challenging to characterize [35].
For common STR genotyping, tools like HipSTR, ExpansionHunter, and GangSTR perform well with both sequencing technologies [35]. However, significant differences emerge for expanded repeats that exceed read lengths. Evaluation of tools for detecting large repeat expansions revealed that ExpansionHunter denovo (EHdn), STRling, and GangSTR outperformed STRetch, with EHdn and STRling using considerably less processor time compared to GangSTR [35]. This performance differential highlights the importance of tool selection for specific repeat analysis applications.
Long-read technologies provide inherent advantages for repetitive element characterization by spanning entire repeat arrays and their flanking regions. This capability enables more accurate length determination and sequence characterization for repeats of all sizes. The limitations of short-read approaches become particularly apparent in regions with segmental duplications and low mappability, where accurate read alignment is problematic [32] [36]. Fully phased genome assemblies using long-read whole-genome sequencing have identified a significant number of variants in repetitive regions that were not observed in short-read data [32].
Gene Fusion Detection
Gene fusions represent hybrid genes formed through structural rearrangements that join two originally separate genes, creating novel chimeric sequences [30] [37]. These events are particularly important in cancer, where they can drive oncogenesis and serve as therapeutic targets. Detection approaches have historically relied on RNA sequencing to identify fusion transcripts, but DNA-based detection provides complementary information about genomic rearrangements.
A multi-tool pipeline (FindDNAFusion) developed for DNA-based fusion detection demonstrated how combinatorial approaches improve accuracy. When individual tools (JuLI, Factera, and GeneFuse) detected 94.1%, 88.2%, and 66.7% of expected fusions respectively, their integration in a coordinated pipeline improved detection accuracy to 98.0% for intron-tiled genes [37]. This highlights the value of multi-algorithm approaches for comprehensive fusion detection.
Long-read RNA sequencing offers unique advantages for fusion characterization by enabling full-length transcript sequencing without assembly. This approach preserves complete transcript structure, allowing direct observation of fusion junctions and their functional consequences [7] [33]. The preservation of full-length transcripts also facilitates the identification of alternative splicing patterns associated with fusion events and provides isoform resolution that is challenging with short-read approaches [7] [6].
Case Studies and Clinical Applications
Rare Genetic Disorders
Complex structural variants play a significant role in rare genetic disorders, though their prevalence and characteristics remain incompletely understood due to historical detection challenges. A comprehensive analysis of whole-genome sequencing data from 12,568 families with rare disorders identified 1,870 de novo SVs, with complex SVs (8.4%) emerging as the third most common type following simple deletions and duplications [36]. Notably, 12% of exon-disrupting pathogenic dnSVs and 22% of de novo deletions or duplications previously identified by array-based or whole-exome sequencing were found to be complex SVs [36]. This finding underscores the limitations of conventional approaches and the importance of specific genomic analysis to avoid overlooking these complex variants.
The study further demonstrated that among probands with de novo SVs, 9% exhibited exon-disrupting pathogenic SVs associated with their phenotype [36]. The greater enrichment of SVs in probands without diagnostic SNVs/indels suggests that a significant proportion of unsolved rare disease cases may be explained by complex SVs that evade detection with standard approaches. These findings highlight the clinical value of comprehensive SV detection in diagnostic odyssey cases.
Cancer Genomics
In cancer genomics, structural variants contribute to oncogenesis through diverse mechanisms including gene fusions, regulatory element rearrangements, and copy number alterations [30] [33]. The ability to resolve complex cancer-associated rearrangements has important implications for diagnosis, prognosis, and treatment selection. DNA-based fusion detection approaches are particularly valuable when RNA is unavailable, with targeted sequencing panels incorporating intronic bait probes against genes commonly involved in oncogenic fusions [37].
Long-read sequencing technologies facilitate the characterization of complex cancer genomes, including chromothripsis events involving localized chromosomal shattering and random reassembly [30]. These catastrophic genomic events can generate multiple fusion events and complex rearrangements that are challenging to reconstruct from short-read data. The progressive improvement in long-read accuracy and throughput now enables more comprehensive analysis of cancer structural variants in both research and clinical contexts.
Experimental Design and Methodological Considerations
Protocol Selection Guidelines
Selecting appropriate experimental protocols requires careful consideration of research objectives, genomic features of interest, and available resources. For comprehensive structural variant discovery, long-read sequencing approaches are generally superior, particularly for variants in repetitive regions and complex rearrangements [32] [33] [36]. However, short-read technologies may suffice for targeted applications in non-repetitive regions or when cost constraints preclude long-read approaches.
For repetitive element analysis, the choice of methodology depends on repeat size and genomic context. Common STRs can be genotyped effectively with both technologies, but expanded repeats typically require long-read approaches or specialized short-read tools that leverage paired-end distance information [35]. Gene fusion detection benefits from multi-platform approaches, with DNA sequencing identifying structural rearrangements and RNA sequencing confirming expression and isoform structure.
Technical Recommendations
Based on comparative studies, we recommend the following technical considerations for resolving complex genomic regions:
- Sequencing Coverage: 30-60x coverage for comprehensive SV detection, with higher coverage (≥50x) beneficial for short-read approaches in complex regions [32] [34]
- Read Length: Longer reads generally improve performance for complex regions; PacBio HiFi reads of 15-20kb effectively span most human SVs [33]
- Sample Quality: High molecular weight DNA is critical for long-read approaches; DNA degradation disproportionately affects long-read performance
- Multi-Algorithm Approaches: Combining multiple detection tools improves sensitivity and precision for all variant types [37] [34]
- Experimental Validation: Orthogonal validation (PCR, optical mapping) remains valuable for complex or clinically significant variants
Integrated Workflow for Complex Genomic Region Analysis
The following diagram illustrates a recommended experimental workflow for comprehensive analysis of complex genomic regions, integrating both short-read and long-read approaches where possible:
Research Reagent Solutions
Table 3: Essential Research Reagents and Resources for Genomic Analysis
| Reagent/Resource | Function | Example Applications |
|---|---|---|
| 10x Genomics Chromium | Single-cell partitioning | Single-cell RNA sequencing, full-length cDNA synthesis [7] |
| MAS-ISO-seq/Kinnex | Transcript concatenation | Increased throughput for full-length isoform sequencing [7] |
| Spike-in RNA controls (Sequins, SIRVs) | Quality control and quantification | Protocol performance assessment, normalization [6] |
| Target enrichment panels | Gene-specific sequencing | Fusion detection in cancer genes [37] |
| PCR-free library prep | Reduced amplification bias | Improved coverage uniformity in repetitive regions |
| Phasing technologies | Haplotype resolution | Determining variant inheritance and compound heterozygosity |
The resolution of complex genomic regions has advanced significantly with the maturation of long-read sequencing technologies and specialized computational methods. While short-read approaches remain valuable for many applications, particularly in non-repetitive regions and with constrained budgets, long-read technologies demonstrate superior performance for comprehensive structural variant detection, repetitive element analysis, and complex rearrangement characterization. The integration of multiple detection algorithms and, where feasible, multi-platform approaches provides the most comprehensive solution for challenging genomic regions.
As sequencing technologies continue to evolve, with improvements in read length, accuracy, and throughput, our ability to resolve complex genomic regions will further enhance understanding of genetic variation and its functional consequences. Researchers should consider their specific biological questions, variant types of interest, and available resources when selecting methodological approaches for studying structural variants, repetitive sequences, and gene fusions.
The field of transcriptomics has evolved from bulk RNA sequencing, which provides an averaged gene expression profile from a tissue, to high-resolution technologies that capture biological information at the single-cell level and beyond. This progression has enabled researchers to uncover cellular heterogeneity, map developmental trajectories, and discover novel cell types and states. Within this context, two pivotal technological advancements have emerged: single-cell RNA sequencing (scRNA-seq) for profiling cellular diversity, and long-read direct RNA sequencing for comprehensive transcript characterization, including the detection of RNA modifications—a field known as epitranscriptomics.
The fundamental distinction between short-read and long-read sequencing technologies underlies this evolution. Short-read sequencing (exemplified by Illumina platforms) provides high-throughput, high-accuracy data at the gene level but typically misses isoform-level information and RNA modifications. Long-read sequencing (exemplified by Pacific Biosciences [PacBio] and Oxford Nanopore Technologies [ONT]) sequences entire RNA molecules, enabling the identification of full-length transcript isoforms and the direct detection of chemical modifications on RNA bases. This guide objectively compares the performance, applications, and experimental requirements of these advanced methodologies within the framework of RNA research.
Technology Comparison: Short-Read vs. Long-Read scRNA-seq
Core Methodological Principles
Short-read scRNA-seq (e.g., 10x Chromium, BD Rhapsody) relies on sequencing short fragments (typically 50-300 bp) from the 3' or 5' ends of transcripts. These platforms use unique molecular identifiers (UMIs) to tag individual mRNA molecules during reverse transcription, allowing for digital counting and quantification of gene expression. The high accuracy (often >Q30) and massive throughput of short-read platforms make them ideal for profiling gene expression in thousands to millions of cells.
Long-read scRNA-seq (e.g., PacBio MAS-ISO-seq, ONT direct RNA-seq) sequences full-length cDNA or native RNA molecules, preserving the complete sequence of individual transcripts. PacBio's HiFi sequencing achieves high accuracy (Q30+) through circular consensus sequencing, while ONT sequences RNA directly by measuring changes in ionic current as molecules pass through protein nanopores. This allows for the simultaneous detection of sequence, splice variants, and base modifications.
Performance Metrics and Experimental Data
Recent studies have directly compared these platforms using standardized samples. The table below summarizes key performance characteristics based on experimental data.
Table 1: Performance comparison of short-read and long-read scRNA-seq platforms
| Performance Metric | Short-Read Platforms (e.g., 10x, BD Rhapsody) | Long-Read Platforms (e.g., PacBio, ONT) |
|---|---|---|
| Read Length | 50-300 bp [17] | 5,000-30,000+ bp [17] |
| Sequencing Accuracy | Very High (Q30-Q40+) [17] | Variable; PacBio HiFi: Very High (Q30-Q40+) [17] |
| Genes Detected per Cell | Similar between platforms in complex tissues [38] | Highly comparable to short-reads [7] |
| UMIs Recovered per Cell | Generally higher [7] | Slightly lower [7] |
| Isoform Resolution | No [7] | Yes [7] |
| RNA Modification Detection | No (requires indirect inference) | Yes (direct detection on native RNA) [39] [40] |
| Cell Type Representation | Platform-specific biases (e.g., lower granulocyte sensitivity in 10x) [38] | Biases differ due to full-length transcript recovery [7] |
| Ambient RNA Contamination | Source is droplet-based [38] | Enables filtering of truncated cDNA artifacts [7] |
A 2025 study compared short-read (Illumina) and long-read (PacBio) sequencing of the same 10x Genomics 3' cDNA libraries from patient-derived organoid cells. The research found that while short reads provided higher sequencing depth and generally recovered more UMIs per cell, the data from both methods were "highly comparable" and yielded "corresponding results" for cell type identification and relevant gene expression patterns [7]. However, platform-specific processing introduced distinct biases; long-read sequencing allowed retention of transcripts shorter than 500 bp and bioinformatic removal of a large proportion of truncated cDNA contaminated by template switching oligos (TSO) [7].
Another 2024 study comparing 10x Chromium and BD Rhapsody in complex tumors highlighted that both platforms have similar gene sensitivity, but exhibit different cell type detection biases. For instance, BD Rhapsody detected a lower proportion of endothelial and myofibroblast cells, while 10x Chromium had lower gene sensitivity in granulocytes [38]. The source of ambient noise also differed between the droplet-based (10x) and plate-based (BD Rhapsody) platforms [38].
Experimental Protocol for Cross-Platform Comparison
The methodology for a direct platform comparison, as described by Pojskic et al. (2025), involves several key steps [7]:
- Sample Preparation: Single-cell full-length cDNA is generated using the 10x Genomics Chromium Single Cell 3' Reagent Kits (v3.1 Chemistry Dual Index). Organoids or tissues are dissociated, washed, and resuspended. Cells are partitioned into nanoliter-scale Gel Beads-in-Emulsion (GEMs) where reverse transcription occurs, adding cell barcodes and UMIs to all cDNA from a single cell.
- Library Diversification: The same amplified cDNA sample is split for preparation of both Illumina (short-read) and PacBio MAS-ISO-seq (long-read) libraries.
- Illumina Library: cDNA is enzymatically sheared to 200-300 bp, and Illumina adapters are ligated. Sequencing is performed on a NovaSeq 6000 to achieve ~300,000 reads per cell.
- PacBio MAS-ISO-seq Library: 45 ng of cDNA is used with the MAS-ISO-seq kit. A key step involves using a modified PCR primer to incorporate a biotin tag into desired cDNA products, enabling streptavidin-based removal of TSO artifacts. cDNA is then segmented and assembled into long linear arrays (10-15 kb) for efficient sequencing on the Sequel IIe platform.
- Data Analysis: A per-molecule comparison is conducted by matching reads through their cell barcode and UMI. Gene count matrices are generated with platform-specific pipelines (e.g., Cell Ranger for Illumina, Iso-Seq processing for PacBio) and compared for cell recovery, transcript recovery, and gene expression correlation.
Diagram 1: Experimental workflow for cross-platform scRNA-seq comparison.
The Epitranscriptome: A New Layer of Regulation
Defining the Epitranscriptome
The epitranscriptome comprises all post-transcriptional chemical modifications of RNA that regulate its processing, stability, localization, translation, and decay without altering the underlying nucleotide sequence [40] [41]. Over 300 types of RNA modifications have been cataloged, with a crucial subset occurring on messenger RNA (mRNA), where they represent a dynamic and regulatory layer of gene expression control [40]. Dysregulation of these pathways is implicated in diseases including cancer, making them attractive therapeutic targets [41].
Key mRNA Modifications and Their Functions
The table below ranks the most studied mRNA modifications based on prevalence in scientific literature and summarizes their core functions.
Table 2: Key mRNA modifications, ranked by PubMed citation prevalence and functional roles
| Modification | PubMed Prevalence (Relative) | Writer Enzymes | Eraser Enzymes | Primary Functions & Relevance |
|---|---|---|---|---|
| N6-methyladenosine (m⁶A) | Very High [40] | METTL3-METTL14 complex [41] | FTO, ALKBH5 [41] | Balances HSC self-renewal/differentiation; promotes leukemogenesis; regulates MYC, MYB [41]. |
| Pseudouridine (Ψ) | High [40] | Not specified | Not specified | Increases mRNA stability & translation; evades innate immune sensing (RIG-I); therapeutic mRNA design [40]. |
| 5-methylcytidine (m⁵C) | High [40] | Not specified | Not specified | Role in RNA export, translation, stability; links to development and tumorigenesis [40]. |
| A-to-I Editing | High [40] | ADAR1 [41] | Not applicable | Contributes to transcript diversity; immune regulation; ADAR1 upregulation promotes immune evasion in cancer [41]. |
| N7-methylguanosine (m⁷G) | Moderate [41] | METTL1 [41] | Not specified | Cap-specific modification; regulates transcript stability and innate immunity [40] [41]. |
| N4-acetylcytidine (ac⁴C) | Moderate [41] | NAT10 [41] | Not specified | Enhances translation and stability of modified mRNAs; implicated in leukemic progression [41]. |
N6-methyladenosine (m⁶A) is the most abundant and well-studied internal mRNA modification. It is dynamically installed by the METTL3-METTL14 writer complex and removed by the erasers FTO and ALKBH5 [41]. Reader proteins (e.g., YTHDF1-3, YTHDC1) interpret the m⁶A mark to influence mRNA fate. In normal hematopoiesis, m⁶A fine-tunes the balance between hematopoietic stem cell (HSC) self-renewal and differentiation by regulating key transcripts like MYC [41]. In acute myeloid leukemia (AML), METTL3 is an essential gene for cancer cell survival, and its overexpression can promote chemoresistance. Conversely, FTO and ALKBH5 are also frequently upregulated in AML, where they drive leukemogenesis by demethylating and stabilizing oncogenic transcripts like AXL [41].
Pseudouridine (Ψ), an isomer of uridine, enhances mRNA stability and translation efficiency. Critically, it helps mRNA evade detection by innate immune sensors like RIG-I, a property that has been leveraged in the design of therapeutic mRNAs (e.g., mRNA vaccines) [40].
Direct RNA Sequencing for Epitranscriptomics
While antibody-based methods like MeRIP-seq exist for mapping certain modifications, nanopore direct RNA sequencing offers a unique capability to sequence intact RNA molecules and detect modifications directly from native RNA [39] [40]. As an RNA molecule passes through a nanopore, the unique electrical current signal generated by each nucleotide is altered by its chemical modification, allowing for simultaneous sequence and modification detection.
A 2025 preprint evaluated the performance of Oxford Nanopore's updated RNA004 chemistry and Dorado basecaller for detecting RNA modifications. Using a single RNA extraction from the GM12878 B-lymphocyte cell line, the study compared the new RNA004 chemistry to the previous RNA002 version. The Dorado basecaller's models for pseudouridine (Ψ) and N6-methyladenosine (m⁶A) were evaluated against data from in vitro transcribed RNA and synthetic oligonucleotides, achieving 96-98% accuracy and F1-score for pseudouridine and 94-98% accuracy and 96-99% F1-score for m⁶A [39]. This demonstrates that Nanopore direct RNA sequencing can simultaneously detect multiple RNA modification types on individual mRNA strands [39].
Diagram 2: Direct RNA sequencing and modification detection workflow.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key research reagent solutions for advanced RNA applications
| Item / Reagent Solution | Function / Application | Example Platforms/Kits |
|---|---|---|
| 10x Genomics Chromium | High-throughput single-cell partitioning and barcoding for 3' or 5' gene expression. | Chromium Single Cell 3' Reagent Kits (v3.1) [7] [38] |
| BD Rhapsody | High-throughput single-cell analysis using microwell-based cartridge system. | BD Rhapsody Scanner & Kits [38] |
| PacBio MAS-ISO-seq Kit | Prepares 10x Genomics cDNA for long-read sequencing, removes TSO artifacts, creates MAS arrays. | MAS-ISO-seq for 10x Genomics [7] |
| Oxford Nanopore Direct RNA Seq Kit | Prepares libraries for sequencing native RNA molecules for direct modification detection. | Direct RNA Sequencing (RNA004 chemistry) [39] |
| Cell Barcodes & UMIs | Tags all cDNA from a single cell during RT, enabling cell identity tracking and digital mRNA counting. | 10x Barcoded Gel Beads [7] |
| MAS Capture Primer (Biotin) | PCR primer used in MAS-ISO-seq to incorporate biotin tag, enabling streptavidin-based purification and removal of TSO artifacts. | Part of PacBio MAS-ISO-seq Kit [7] |
| METTL3 Inhibitors | Small-molecule inhibitors (e.g., STC-15) to target the m⁶A writer complex for therapeutic discovery. | In early-phase clinical trials (NCT05584111) [41] |
Integrated Application in Drug Development
The journey from target discovery to clinical application strategically leverages the strengths of different sequencing modalities. Single-cell whole transcriptome sequencing (primarily short-read) is an unbiased discovery tool ideal for initial target identification, de novo cell type identification, and constructing comprehensive cell atlases like the Human Cell Atlas [42]. However, its cost, computational complexity, and susceptibility to gene dropout (false negatives for low-abundance transcripts) limit its utility in translational settings [42].
In contrast, single-cell targeted gene expression profiling (e.g., using focused panels of 50-500 genes) and long-read sequencing for specific applications become indispensable in later stages. By concentrating sequencing resources on a pre-defined gene set, targeted profiling achieves superior sensitivity, minimizes gene dropout, and is more cost-effective and scalable for large clinical cohorts [42]. This makes it ideal for:
- Target Validation: Confirming a target's expression across large patient cohorts [42].
- Mechanism of Action (MoA) & Safety: Using targeted panels to assess on-target pathway activity and screen for off-target effects in toxicity pathways [42].
- Biomarker & Companion Diagnostic Development: Creating robust, clinically actionable assays for patient stratification [42].
- Pharmacodynamics: Monitoring therapy-induced gene expression changes at the single-cell level [42].
Long-read sequencing integrates into this workflow by enabling epitranscriptomic profiling in drug response and resistance studies. For instance, detecting specific m⁶A patterns on transcripts like ITGA4 or BCAT1/2, which are linked to chemoresistance and metabolic adaptation in AML, can uncover novel resistance mechanisms and therapeutic vulnerabilities [41].
Optimizing Your RNA-Seq Workflow: From Library Prep to Data Analysis
The conversion of RNA into complementary DNA (cDNA) libraries is a foundational step in RNA sequencing (RNA-seq) that fundamentally influences the quality, accuracy, and interpretability of transcriptomic data. While this process enables high-throughput transcriptome analysis, it introduces numerous platform-specific biases and artifacts that can compromise data integrity if not properly addressed. These technical variations arise from multiple sources, including reverse transcription efficiencies, PCR amplification dynamics, and sequencing chemistry limitations, creating distinct profiles across short-read and long-read technologies. Understanding these platform-specific artifacts is essential for selecting appropriate methodologies, designing robust experiments, and accurately interpreting results in both basic research and drug development contexts. This guide systematically compares these effects across major sequencing platforms, providing researchers with a framework for navigating the complex landscape of modern RNA-seq technologies.
Key Artifacts and Biases in cDNA Library Preparation
Reverse Transcription Biases
The reverse transcription (RT) reaction, which converts RNA to cDNA, introduces substantial biases that propagate through all downstream analyses. Contemporary reverse transcriptases are engineered from retroviral enzymes and retain characteristics that systematically bias representation of the original RNA pool.
RNA Secondary Structure Bias: Reverse transcriptases exhibit varying capabilities in dealing with RNA secondary structure, with more than 100-fold cDNA yield differences observed purely from enzymatic handling of structure [43]. Thermally stable reverse transcriptases operating at higher temperatures can mitigate this bias by disrupting RNA secondary structures during cDNA synthesis [43].
RNase H Activity: The RNase H moiety in many reverse transcriptases hydrolyzes RNA in cDNA:RNA duplexes, potentially causing premature termination and introducing negative bias against longer transcripts [43]. Enzymes with diminished RNase H activity (e.g., Superscript IV, Maxima H Minus) demonstrate superior performance for full-length cDNA synthesis [43].
Primer-Dependent Biases: Primer selection introduces substantial artifacts. Oligo(dT) primers are limited to polyadenylated RNA and create 3'-end bias. Random hexamers exhibit non-random binding capacities dependent on RNA secondary structure and sequence composition [43]. Gene-specific primers provide targeted amplification but show contrasting binding efficiencies between targets [43].
PCR Amplification Artifacts
PCR amplification remains a critical source of bias in library preparation, disproportionately amplifying certain molecules and introducing errors that affect quantification accuracy.
PCR Duplication Effects: The rate of PCR duplicates strongly depends on the combined effect of RNA input material and PCR cycle number [44]. For input amounts below 125 ng, 34-96% of reads may be discarded during deduplication, with percentages increasing with lower input amounts and higher PCR cycles [44]. This reduced read diversity decreases gene detection sensitivity and increases noise in expression counts.
Input Material and Cycle Optimization: Studies comparing NovaSeq 6000, NovaSeq X, AVITI, and G4 sequencers demonstrate that input amounts above 10 ng but below 125 ng show strong negative correlation between input amount and PCR duplicate rates, but positive correlation between PCR cycle number and duplicate rates [44]. The highest quality RNA sequencing is obtained using the lowest recommended number of PCR cycles for amplification [44].
Platform-Specific Amplification Effects: Library conversion for sequencing on different platforms (e.g., converting Illumina libraries for AVITI and G4 sequencers) introduces additional PCR steps that increase duplicate rates, particularly for very low input amounts (<15 ng) [44].
Template-Switching Artifacts
Template switching represents a significant source of artifactual sequences in cDNA libraries, particularly affecting the accurate identification of transcript boundaries.
Artifactual Polyadenylation Sites: Template-switching during reverse transcription can generate spurious polyadenylation sites that resemble genuine alternative polyadenylation [45]. These artifacts occur at consecutive stretches of as few as three adenines, complicating transcript end identification [45].
Distinguishing Artifacts from Genuine Transcripts: Genuine transcriptional end sites are typically preceded by canonical polyadenylation signals, while template-switching artifacts generally lack these signals [45]. Specialized filtering algorithms that consider adenine content in upstream regions, read distribution patterns, and polyadenylated read-to-coverage ratios outperform conventional internal priming filters [45].
Platform-Specific Comparison of cDNA Artifacts
Table 1: Comparative Analysis of cDNA Library Artifacts Across Major Sequencing Platforms
| Platform | Primary Artifacts | Error Profile | Recommended Input | Key Mitigation Strategies |
|---|---|---|---|---|
| Illumina Short-Read | PCR duplicates, GC bias, 3'-bias from oligo(dT) priming | Low per-base error rate (<0.1%) but systematic biases | 10 ng minimum (higher reduces duplicates) | Unique Molecular Identifiers (UMIs), reduced PCR cycles, rRNA depletion [44] [46] |
| PacBio Long-Read | PCR artifacts from library prep, limited throughput | Random indels in homopolymers, improved with HiFi mode | High molecular weight RNA recommended | Circular Consensus Sequencing (CCS), PCR-free protocols where possible [2] [21] |
| Oxford Nanopore | PCR artifacts (if amplified), basecalling inaccuracies | Higher raw error rate (1-5%), context-dependent | Flexible input requirements | Direct RNA sequencing, PCR-free cDNA protocols, homotrimer UMIs [47] [48] |
Table 2: Impact of PCR Cycles on Sequencing Artifacts Across Platforms (Experimental Data)
| PCR Cycles | Input RNA | PCR Duplicate Rate (Illumina) | PCR Duplicate Rate (Converted Libraries) | CMI/UMI Error Rate | Recommended Applications |
|---|---|---|---|---|---|
| Low (8-12) | 125-1000 ng | 3.5-10% | 5-12% | 2-5% | Standard transcriptomics, high-abundance targets |
| Medium (13-17) | 15-125 ng | 10-25% | 15-30% | 5-15% | Low-input samples, single-cell RNA-seq |
| High (18+) | 1-15 ng | 25-96% | 30-96% | 15-40% | Extremely limited samples, clinical specimens |
Methodological Approaches for Bias Mitigation
Unique Molecular Identifiers (UMIs) and Error Correction
UMIs are random oligonucleotide sequences that label individual RNA molecules before amplification, enabling computational correction of PCR biases. However, PCR errors within UMIs themselves can generate inaccuracies in molecular counting.
Homotrimeric UMI Design: Synthesizing UMIs using homotrimeric nucleotide blocks (triplet bases) enables efficient error correction through majority voting, where the most frequent nucleotide in each trimer block determines the corrected sequence [48]. This approach significantly improves UMI recovery rates compared to standard monomeric UMIs—increasing accurate common molecular identifier (CMI) calls from 73.36% to 98.45% on Illumina, 68.08% to 99.64% on PacBio, and 89.95% to 99.03% on Nanopore platforms [48].
PCR Error Impact: Experimental data demonstrates that PCR—not sequencing—is the primary source of UMI errors, with error rates increasing substantially with additional PCR cycles [48]. After 25 PCR cycles, homotrimer correction reduced apparent differentially expressed transcripts from over 300 to zero in controlled comparisons, demonstrating how PCR errors artificially inflate transcript counts [48].
Reverse Transcription Methodologies
Thermostable Reverse Transcriptases: Enzymes engineered for enhanced thermostability (e.g., Superscript IV, Maxima H Minus) improve cDNA yield by disrupting RNA secondary structures during synthesis, particularly for structured RNAs [43].
Template-Switching Reverse Transcription: This approach can improve full-length cDNA coverage but requires careful optimization to avoid the generation of chimeric sequences [45].
Platform-Specific Workflow Optimizations
Diagram 1: cDNA Library Preparation Workflow and Critical Decision Points. Green nodes indicate bias-mitigating approaches, while red nodes represent key artifact risks that require specific countermeasures.
Essential Reagents and Research Solutions
Table 3: Key Research Reagents for cDNA Library Preparation and Artifact Mitigation
| Reagent Category | Specific Examples | Function | Considerations for Bias Reduction |
|---|---|---|---|
| Reverse Transcriptases | Superscript IV, Maxima H Minus | RNA to cDNA conversion | Select enzymes with low RNase H activity and high thermostability for structured RNAs [43] |
| UMI Systems | Homotrimer UMI designs, Commercial UMI kits | Molecular barcoding | Implement error-correcting UMI designs; position at both ends of fragments for enhanced error detection [48] |
| Library Prep Kits | NEBNext Ultra II, Platform-specific kits | Library construction | Match input requirements to sample availability; use minimal PCR cycles [44] |
| RNA Preservation Reagents | RNAlater, Non-cross-linking fixatives | Sample integrity | Avoid formalin-based fixation when possible; minimize freeze-thaw cycles [46] |
| RNA Extraction Methods | mirVana kit, Column-based protocols | RNA isolation | Select methods appropriate for RNA species of interest; TRIzol may cause small RNA loss [46] |
The landscape of cDNA library preparation presents a series of trade-offs where researchers must balance input requirements, throughput, accuracy, and artifact potential against their specific experimental goals. Short-read platforms excel in throughput and per-base accuracy but struggle with amplification biases and transcript isoform resolution. Long-read technologies capture full-length transcripts but face different challenges in basecalling accuracy and library complexity. Across all platforms, fundamental molecular biology principles apply—minimizing PCR cycles, implementing robust UMI strategies with error correction, selecting appropriate reverse transcriptases, and matching input requirements to experimental design. As sequencing technologies continue evolving, the systematic understanding and mitigation of cDNA artifacts remains essential for generating biologically meaningful transcriptomic data in both basic research and drug development applications.
Best Practices in Library Preparation and Quality Control
RNA sequencing (RNA-seq) stands as the cornerstone for differential gene expression (DGE) analysis and transcriptome studies in molecular biology. The foundational workflow commences with RNA extraction, proceeds through library preparation, and culminates in high-throughput sequencing and computational analysis. The critical choice between short-read and long-read technologies represents a fundamental strategic decision that directly influences library preparation protocols and quality control metrics. This guide provides a comprehensive, objective comparison of these approaches within the context of RNA-seq research, enabling researchers, scientists, and drug development professionals to align their experimental designs with appropriate technological capabilities [2].
The conventional RNA-seq workflow begins with RNA extraction from biological samples, followed by mRNA enrichment or ribosomal RNA depletion to focus sequencing efforts on informative transcripts. Subsequent steps include cDNA synthesis and construction of adapter-ligated sequencing libraries, which are then subjected to high-throughput sequencing. The resulting data undergoes computational alignment or assembly, transcript quantification, normalization, and statistical modeling to identify significant expression changes across experimental conditions. Throughout this process, library preparation quality directly determines the reliability, accuracy, and interpretability of final results [2] [49].
Technology Platform Comparison: Short-Read vs. Long-Read RNA-Seq
Fundamental Technological Differences
Short-read sequencing (exemplified by Illumina and Ion Torrent platforms) involves parsing DNA or RNA into fragments typically ranging from 50-300 base pairs. This approach generates millions of reads with very high accuracy through massive parallel sequencing. In contrast, long-read sequencing (including PacBio and Oxford Nanopore technologies) captures much longer DNA or RNA fragments spanning thousands to hundreds of thousands of base pairs. This capability provides more comprehensive coverage of transcripts but comes with different error profiles and throughput considerations [2] [50].
The selection between these technologies involves strategic trade-offs. Short-read platforms offer high throughput at lower cost, making them suitable for large-scale studies, while long-read technologies excel at resolving complex genomic regions, identifying structural variations, and capturing full-length transcripts without assembly requirements. Each method presents distinct advantages that recommend it for specific research applications, with a hybrid approach sometimes providing the most comprehensive understanding of complex transcriptomes [2].
Comparative Performance Specifications
Table 1: Direct comparison of short-read and long-read RNA sequencing technologies
| Parameter | Short-Read cDNA-Seq | Long-Read cDNA-Seq | Long-read RNA-Seq |
|---|---|---|---|
| Platforms | Illumina, Ion Torrent | PacBio | Oxford Nanopore |
| Read Length | 50-300 bp | 1-50 kb | 1-50 kb |
| Throughput | Very high (100-1000x more reads per run than long-read) | Low to medium (500,000 to 10M reads per run) | Low to medium (500,000 to 1M reads per run) |
| Accuracy | High | Medium (improved with circular consensus) | Medium (higher error rates) |
| Key Advantages | - High throughput- Well-understood bias and error profiles- Multiple computational workflows for degraded RNA- Cost-effective for large studies | - Captures full-length transcripts- Simplifies computational analysis- Excellent for isoform discovery | - Direct RNA sequencing without reverse transcription- Detects RNA base modifications- Enables Poly(A) tail length estimation |
| Key Limitations | - Limited isoform detection- Assembly required for transcript discovery- Sample preparation introduces bias | - Lower throughput- Sample preparation biases- Not recommended for degraded RNA | - Lower throughput- Incomplete understanding of sequencing biases- Higher cost per sample |
| Optimal Applications | - Differential gene expression- Small RNA analysis- Single-cell RNA-seq- Spatial transcriptomics | - Isoform discovery- Fusion transcript detection- Complex transcript analysis (MHC/HLA) | - Isoform discovery- RNA modification detection- Fusion transcript detection- Direct RNA analysis |
Library Preparation Protocols: Methodological Approaches
Core Workflow and Common Initial Steps
All RNA-seq library preparations share fundamental steps regardless of the sequencing technology eventually employed. The process begins with RNA extraction and quality assessment, followed by enrichment of desired RNA species or depletion of unwanted RNA (typically ribosomal RNA). For most applications focusing on protein-coding genes, researchers target polyadenylated transcripts through poly(A) selection, though ribosomal RNA depletion provides alternative strategies for capturing non-polyadenylated RNAs. The critical divergence between short-read and long-read protocols occurs primarily at the cDNA synthesis and adapter integration stages [49].
A crucial consideration across all protocols is the handling of enzymatic reactions. Proper enzyme stability and cold chain management must be maintained by keeping enzymes at recommended temperatures and avoiding repeated freeze-thaw cycles. Accurate pipetting is essential for consistent and reproducible results, with automated liquid handling systems significantly minimizing human error potential. These fundamental practices ensure that library quality remains high before protocol-specific steps are implemented [51].
Short-Read RNA-seq Library Preparation
The dominant approach for short-read library preparation involves fragmenting RNA or cDNA, synthesizing cDNA, and ligating platform-specific adapters. The TruSeq library prep method (Illumina) represents a widely used protocol that incorporates unique molecular identifiers to enable multiplexing of samples. Following fragmentation, cDNA synthesis creates stable DNA representations of RNA transcripts, with subsequent steps adding platform-compatible adapters and sample-specific barcodes. The final libraries are amplified, normalized, and quantified before sequencing [49] [52].
A critical quality consideration for short-read protocols involves adapter ligation optimization. Using freshly prepared or properly stored adapters prevents degradation and ensures efficient ligation. Controlled ligation temperature and duration maximize yields, with blunt-end ligations typically performed at room temperature for 15-30 minutes, while cohesive-end ligations often require lower temperatures (12-16°C) and extended incubation. Maintaining correct molar ratios of adapters to insert reduces formation of adapter dimers that would otherwise compromise sequencing efficiency [51].
Long-Read RNA-seq Library Preparation
Long-read technologies offer multiple preparation approaches, each with distinct advantages. The PCR-amplified cDNA protocol requires the least input RNA and generates the highest throughput, making it suitable for samples with limited starting material. When sufficient RNA is available, the amplification-free direct cDNA protocol eliminates PCR amplification biases. For Oxford Nanopore platforms, the direct RNA-seq protocol sequences native RNA without reverse transcription, preserving base modifications and enabling direct detection of RNA modifications such as N6-methyladenosine (m6A) [6].
The PacBio Iso-Seq protocol employs a unique approach involving reverse transcription with oligonucleotide primers to create full-length cDNA, followed by SMRTbell adapter ligation for circular consensus sequencing. This method generates highly accurate long reads by sequencing the same molecule multiple times, though at reduced throughput compared to short-read methods. For all long-read approaches, careful quality control at the RNA integrity step is crucial, as degradation significantly impacts the ability to generate full-length transcripts [19].
Quality Control and Validation Strategies
Critical Quality Control Checkpoints
Robust quality control throughout library preparation is essential for generating reliable sequencing data. Key checkpoints include post-ligation validation to ensure adapter integration efficiency, post-amplification quantification to verify adequate library yield, and pre-sequencing normalization to ensure balanced representation of multiplexed samples. Validation methods such as fragment analysis, qPCR, and fluorometry assess library quality at these stages, enabling early detection of issues before costly sequencing runs [51].
Library normalization represents a particularly critical quality control step before pooling samples for sequencing. Accurate normalization ensures each library contributes equally to the final sequencing pool, preventing under- or over-representation that could introduce technical biases and compromise data interpretation. Automated normalization systems significantly improve consistency across pooled samples compared to manual quantification and dilution approaches, which are time-consuming and introduce operator-dependent variability [51].
Technology-Specific Quality Considerations
Each sequencing technology presents unique quality control requirements. For short-read sequencing, assessing fragment size distribution and confirming the absence of adapter dimers is crucial. The high throughput of these platforms enables robust statistical sampling of expression levels, but requires careful monitoring of base quality scores across sequencing cycles. For long-read sequencing, RNA integrity number (RIN) values ≥7 are typically required to ensure successful full-length transcript capture, with special attention to input RNA quality being essential [19].
The recent Singapore Nanopore Expression (SG-NEx) project established comprehensive benchmarking for long-read RNA-seq quality assessment, including spike-in controls with known concentrations to evaluate quantification accuracy across protocols. Their findings indicate that long-read RNA-seq more robustly identifies major isoforms compared to short-read approaches, though with higher variability in quantification accuracy between technical replicates. Systematic quality control measures are particularly important for long-read data due to the technology's higher error rates and less established bias profiles compared to mature short-read platforms [6].
Table 2: Quality control recommendations for different RNA-seq applications
| QC Parameter | Gene Expression Profiling | Transcriptome Assembly | Isoform Detection | Small RNA Analysis |
|---|---|---|---|---|
| Recommended Read Depth | 5-25 million reads for snapshot; 30-60 million for global view | 100-200 million reads | 30-100 million reads (technology dependent) | 1-5 million reads |
| RNA Quality Requirement | RIN ≥7 | RIN ≥8 | RIN ≥8 for long-read | Focus on small RNA fraction |
| Library QC Focus | Fragment size distribution, absence of adapter dimers | Insert size distribution, representation of long transcripts | Full-length transcript coverage, minimal amplification bias | Specific adapter ligation efficiency |
| Sequencing QC Metrics | Balanced base composition, high Q30 scores, even coverage | Read length distribution, alignment rates to reference | Isoform classification against reference annotations | Size distribution matching expected small RNAs |
| Validation Approach | qPCR confirmation of selected genes | Comparison with existing transcript models | Orthogonal validation by RT-PCR | Spike-in controls for quantification |
Experimental Design and Applications
Matching Technology to Research Objectives
The choice between short-read and long-read sequencing should be driven primarily by research goals rather than technical considerations alone. Short-read RNA-seq remains the gold standard for differential gene expression studies, particularly when analyzing large sample sets where cost-effectiveness and high throughput are prioritized. Its well-established protocols and analytical frameworks make it ideal for gene-level expression profiling, small RNA analysis, and single-cell transcriptomics [2] [52].
Long-read RNA-seq excels in applications requiring transcript-level resolution, including isoform discovery, fusion transcript detection, and characterization of complex gene families (such as MHC and HLA genes). A recent systematic benchmark demonstrated that long-read sequencing more robustly identifies major isoforms compared to short-read approaches, with Nanopore long-read protocols particularly valuable for detecting RNA base modifications and enabling direct RNA sequencing without reverse transcription or amplification steps [2] [6].
Integrated and Hybrid Approaches
Increasingly, researchers are adopting integrated approaches that leverage both short-read and long-read technologies within the same study. A 2025 investigation of mouse retina transcriptomes exemplified this strategy, profiling approximately 30,000 cells using both Illumina short reads and Oxford Nanopore long reads. This integrated approach identified 44,325 transcript isoforms, with 38% being previously uncharacterized and 17% expressed exclusively in distinct cellular subclasses [53].
Such integrated designs capitalize on the complementary strengths of each technology: short-read data provide high-accuracy gene expression quantification, while long-read data resolve transcript isoform structures. The resulting hybrid datasets enable more comprehensive transcriptome annotation, particularly for alternative splicing analysis and novel transcript discovery. This approach is especially valuable in disease research, where both gene expression changes and isoform switching may contribute to pathological mechanisms [53] [19].
Essential Research Reagent Solutions
Table 3: Key reagents and materials for RNA-seq library preparation
| Reagent/Category | Function | Technology Application |
|---|---|---|
| Poly(A) Selection Beads | Enriches for polyadenylated mRNA transcripts | Both short-read and long-read |
| Ribosomal Depletion Kits | Removes abundant ribosomal RNA | Both short-read and long-read |
| Reverse Transcriptase | Synthesizes cDNA from RNA templates | Both short-read and long-read |
| Fragmentase Enzyme | Controls RNA or cDNA fragmentation size | Primarily short-read |
| Platform-Specific Adapters | Enables binding to sequencing flow cells | Platform-specific |
| Unique Molecular Identifiers | Tags individual molecules for quantification | Both (more common in short-read) |
| SMRTbell Adapters | Circular consensus sequencing templates | PacBio long-read |
| dNTP/NTP Mixes | Building blocks for synthesis | Both short-read and long-read |
| RNAse Inhibitors | Protects RNA integrity during processing | Both short-read and long-read |
| Size Selection Beads | Selects appropriate fragment sizes | Both short-read and long-read |
| Library Quantification Kits | Measures library concentration accurately | Both short-read and long-read |
Library preparation represents the foundational step that determines success in RNA-seq experiments, with quality control practices directly influencing data reliability and interpretability. The choice between short-read and long-read technologies involves strategic trade-offs between throughput, cost, resolution, and analytical complexity. Short-read methods provide established, cost-effective solutions for gene expression profiling, while long-read technologies offer unprecedented resolution for transcript isoform characterization.
Future methodological developments will likely continue to blur the distinctions between these approaches through integrated workflows and hybrid analyses. By implementing rigorous quality control measures, selecting appropriate protocols for specific research questions, and leveraging the complementary strengths of different sequencing technologies, researchers can maximize insights from transcriptome studies while ensuring reproducible, high-quality data generation.
A Guide to Computational Tools for Short-Read and Long-Read Data Analysis
RNA sequencing (RNA-seq) has become a foundational technology for profiling gene expression, but researchers now face a critical choice between short-read and long-read technologies. Short-read RNA-seq, dominated by Illumina platforms, generates high-throughput, high-accuracy reads typically 50-300 base pairs long, but requires fragmentation of mRNA molecules, losing connectivity between distant exons [4]. In contrast, long-read technologies from Pacific Biosciences (PacBio) and Oxford Nanopore Technologies (ONT) sequence full-length transcripts in single reads, enabling direct observation of splice variants without reconstruction [4] [54]. This fundamental difference has driven the development of distinct computational tools optimized for each data type.
The complexity of the human transcriptome makes this technological choice particularly significant. Over 95% of multi-exon genes undergo alternative splicing, with genes averaging four different transcriptional start sites and over 70% of genes subject to alternative polyadenylation [4]. This generates enormous diversity from approximately 20,000 protein-coding genes, which can encode over 300,000 unique protein isoforms [4]. Long-read sequencing technologies directly capture this complexity by sequencing complete transcripts from end to end, providing a transformative approach for exploring transcriptome variations in both basic research and disease contexts [4].
Technology Comparison: Key Differences and Applications
Platform Characteristics and Performance Metrics
Table 1: Comparison of RNA Sequencing Technologies
| Feature | Illumina Short-Read RNA-seq | PacBio Long-Read RNA-seq | ONT Long-Read RNA-seq |
|---|---|---|---|
| Read Length | 50-300 bp [4] | Up to 25 kb [4] | Up to 4 Mb [4] |
| Base Accuracy | 99.9% [4] | 99.9% (HiFi) [4] | 95%-99% (R10.4 chemistry) [4] |
| Throughput | 65-3,000 Gb per flow cell [4] | Up to 90 Gb per SMRT cell [4] | Up to 277 Gb per PromethION flow cell [4] |
| Key Applications | Gene-level expression quantification, differential expression analysis [6] [4] | Full-length isoform detection, novel transcript discovery, variant detection [22] [4] [54] | Direct RNA sequencing, RNA modification detection, real-time analysis [6] [4] [54] |
| Strengths | High throughput, low cost per base, established analysis pipelines [4] | High consensus accuracy, excellent for isoform resolution [4] [54] | Ultra-long reads, direct RNA modification detection, portability [4] [54] |
Experimental Evidence from Benchmarking Studies
Recent large-scale consortium efforts have systematically evaluated the performance of different RNA-seq technologies. The Singapore Nanopore Expression (SG-NEx) project profiled seven human cell lines with five different RNA-seq protocols, including short-read cDNA, Nanopore direct RNA, direct cDNA, PCR-amplified cDNA sequencing, and PacBio IsoSeq [6] [55]. This comprehensive benchmark revealed that long-read protocols, particularly PCR-amplified cDNA sequencing and PacBio IsoSeq, showed the most uniform coverage across transcript length and the highest proportion of reads spanning all exon junctions ("full-splice-match reads") [55]. Meanwhile, short-read RNA-seq had the highest fraction of reads that could be assigned to multiple transcripts, reflecting the inherent ambiguity in transcript assignment when working with fragmented sequences [55].
The Long-read RNA-Seq Genome Annotation Assessment Project (LRGASP) Consortium generated over 427 million long-read sequences from complementary DNA and direct RNA datasets to evaluate effectiveness for transcriptome analysis [22]. Their findings revealed that libraries with longer, more accurate sequences produce more accurate transcripts than those with increased read depth, whereas greater read depth improved quantification accuracy [22]. In well-annotated genomes, tools based on reference sequences demonstrated the best performance, with the consortium recommending incorporating additional orthogonal data and replicate samples when aiming to detect rare and novel transcripts or using reference-free approaches [22].
Computational Tools for RNA-seq Analysis
Tool Selection Based on Data Type and Research Goals
The choice of computational tools depends heavily on the sequencing technology used and the specific research objectives. For short-read data, the focus has been on accurate alignment and quantification despite the inherent limitations of fragmentary data, while long-read tools leverage the full-length information to directly characterize transcript isoforms.
Table 2: Computational Tools for RNA-seq Analysis
| Tool | Compatibility | Primary Function | Key Features | Benchmark Performance |
|---|---|---|---|---|
| Kallisto [56] | Short-read | Pseudoalignment and quantification | Ultra-fast, alignment-free using de Bruijn graphs | High accuracy and speed in isoform quantification |
| Salmon [56] | Short-read | Transcript quantification | Two-phase inference with online/offline EM algorithms | Fast and accurate, can use its own mapper or BAM files |
| RSEM [56] | Short-read | Transcript quantification | Expectation-Maximization algorithm for read assignment | High accuracy but computationally intensive |
| StringTie2 [4] | Long-read | Transcript assembly and quantification | Reference-based transcript assembly | Performs well in well-annotated genomes |
| IsoQuant [4] | Long-read | Transcript identification and quantification | Handles complex splicing patterns, works with PacBio and ONT | Good performance in LRGASP benchmark [22] |
| Bambu [4] | Long-read | Transcript discovery and quantification | Uses machine learning to identify novel transcripts | Suitable for reference-free approaches |
| ESPRESSO [4] | Long-read | Transcript refinement and quantification | Aggregates information across reads to refine alignments | Improved discovery of novel isoforms |
| FLAMES [4] | Long-read | Full-length transcript analysis | End-to-end workflow for isoform sequencing | Good performance in LRGASP benchmark [22] |
Specialized Tools for Single-Cell RNA-seq
The rise of single-cell RNA sequencing has further expanded the tool ecosystem, with specialized packages designed to handle the unique characteristics of single-cell data:
- Cell Ranger: The standard for preprocessing 10x Genomics data, transforming raw FASTQ files into gene-barcode count matrices using the STAR aligner [57].
- Seurat: A comprehensive R toolkit supporting data integration across batches, tissues, and modalities, with expansion to spatial transcriptomics and multiome data [57].
- Scanpy: A Python-based framework optimized for large-scale datasets, integrating seamlessly with other Python tools for statistical modeling and visualization [57].
- Velocyto: Introduces RNA velocity by quantifying spliced and unspliced transcripts to infer future transcriptional states of individual cells [57].
- scvi-tools: Uses deep generative modeling with variational autoencoders to model noise and latent structure of single-cell data, providing superior batch correction [57].
A 2025 comparison of single-cell long-read and short-read sequencing found that both methods render highly comparable results for gene expression, despite platform-dependent biases in library processing and data analysis [7]. Short-read sequencing provided higher sequencing depth, but long-read sequencing allowed for retaining transcripts shorter than 500 bp and for removal of degraded cDNA contaminated by template switching oligos [7].
Experimental Design and Workflows
Standardized Processing Pipelines
To ensure reproducible analysis of long-read RNA-seq data, community-curated pipelines have been developed. The nf-core/nanoseq pipeline provides a streamlined workflow for processing long-read RNA-seq data, performing quality control, alignment, transcript discovery and quantification, differential expression analysis, RNA fusion detection, and RNA modification detection [55]. Each module provides options to use different existing methods that can be seamlessly integrated, with dynamic testing on full-sized datasets and execution through Docker, Singularity, or cloud environments [55].
Diagram 1: Comparative analysis workflows for short-read and long-read RNA-seq data.
Key Research Reagents and Materials
Table 3: Essential Research Reagents for RNA-seq Experiments
| Reagent/Solution | Function | Application Notes |
|---|---|---|
| Spike-in RNA Controls (ERCC, SIRV, Sequin) [6] [55] | Quality control and quantification calibration | Enable evaluation of technical performance and accuracy across protocols |
| Poly(A) Selection Beads | mRNA enrichment from total RNA | Critical for capturing protein-coding transcripts; potential source of bias |
| Reverse Transcriptase Enzymes | cDNA synthesis from RNA templates | Enzyme choice affects read length and coverage uniformity |
| Template Switching Oligos (TSO) [7] | cDNA amplification in single-cell protocols | Can cause artifacts; long-read protocols enable their removal |
| DNA Damage Repair Mix | Library preparation for PacBio MAS-ISO-seq | Essential for producing high-quality concatenated arrays for sequencing |
| Solid-Phase Reversible Immobilization (SPRI) Beads | Size selection and cleanup | Critical for removing short fragments and reaction components |
Performance Benchmarks and Practical Recommendations
Quantification Accuracy Across Platforms
The SG-NEx project conducted systematic comparisons of quantification accuracy using spike-in RNAs with known concentrations. Their findings revealed that Nanopore long-read RNA-seq data showed the lowest estimation error overall and higher correlation with expected concentrations compared to other protocols [55]. However, different protocols exhibited distinct biases: PCR-amplified cDNA sequencing was enriched for highly expressed genes, while PacBio IsoSeq showed significant depletion of shorter transcripts [55]. The direct RNA-seq protocol starts sequencing at the poly(A) tail, resulting in higher coverage at the 3' end compared to the 5' end [55].
The LRGASP consortium evaluation of 14 computational tools revealed that no single tool emerged as a clear frontrunner across all applications [22] [4]. Different tools excelled for different objectives, with some optimized for quantifying annotated transcript isoforms and others more receptive to discovering novel isoforms [4]. The consortium found that obtaining full-length and highly accurate reads was more important for transcript identification than simply increasing sequencing depth [4].
Decision Framework for Tool Selection
Diagram 2: Decision framework for selecting RNA-seq tools based on research objectives.
Based on comprehensive benchmarking studies, the following recommendations emerge for selecting computational tools:
For well-annotated genomes and quantification purposes: Reference-based tools like StringTie2 and IsoQuant generally provide the most accurate results, particularly when using long-read data [22] [4].
For novel transcript discovery: Tools designed for reference-free approaches, such as Bambu, show better performance for identifying previously unannotated isoforms [22] [4].
When using short-read data exclusively: Alignment-free tools like Kallisto and Salmon provide the best combination of speed and accuracy for isoform quantification [56].
For single-cell multi-omics: Seurat and Scanpy offer the most comprehensive integration capabilities, supporting simultaneous analysis of transcript expression and isoform information [57].
For detection of RNA modifications: Oxford Nanopore direct RNA sequencing coupled with specialized tools is uniquely capable, as it sequences native RNA without cDNA conversion [6] [4].
As sequencing technologies continue to evolve, the distinction between short-read and long-read approaches may blur, with hybrid strategies becoming increasingly common. The development of more sophisticated computational tools that can leverage the complementary strengths of both technologies will further enhance our ability to unravel the complexity of transcriptomes in health and disease.
Hybrid and Targeted Sequencing Strategies to Maximize Value and Resolution
In the evolving landscape of genomics research, targeted sequencing has emerged as a powerful technique that enables researchers to focus on specific genomic regions of interest, providing deeper coverage at a lower cost compared to whole-genome sequencing [58]. This approach is particularly valuable for applications ranging from rare variant identification in clinical diagnostics to zoonotic pathogen detection within the One Health framework [59]. The choice between different targeted enrichment methods—primarily hybridization-based capture and amplicon sequencing—presents researchers with critical trade-offs in specificity, uniformity, and experimental workflow complexity [60] [58].
Framed within the broader context of short-read versus long-read sequencing technologies, these targeted strategies offer complementary strengths that can be leveraged to maximize both value and resolution in transcriptomic studies [6]. While short-read sequencing has traditionally provided high-throughput, cost-effective solutions for gene-level expression analysis, long-read technologies are increasingly demonstrating their unique value in resolving complex isoform-level expression, fusion transcripts, and RNA modifications [7] [6]. This guide objectively compares the performance characteristics of different targeted sequencing approaches, supported by experimental data, to inform researchers, scientists, and drug development professionals in selecting optimal strategies for their specific research applications.
Method Comparison: Hybridization Capture vs. Amplicon Sequencing
Targeted sequencing methods differ significantly in their underlying technologies, workflows, and performance characteristics. The two primary approaches—hybridization-based capture and amplicon sequencing—each offer distinct advantages depending on the research objectives, target size, and required sensitivity [58].
Table 1: Core Method Comparison between Hybridization Capture and Amplicon Sequencing
| Feature | Hybridization Capture | Amplicon Sequencing |
|---|---|---|
| Principle | Solution-based hybridization with biotinylated oligonucleotide probes [60] | PCR amplification of target regions using specific primers [60] |
| Number of Steps | More steps involved [58] | Fewer steps, streamlined workflow [58] |
| Target Capacity | Virtually unlimited by panel size [58] | Flexible, usually fewer than 10,000 amplicons [58] |
| Typical Applications | Exome sequencing, rare variant identification, oncology research [58] | Germline SNP/indel detection, known fusion identification, CRISPR edit verification [58] |
| On-target Rate | High but generally lower than amplicon [58] | Naturally higher due to primer-specific amplification [58] |
| Uniformity | Greater coverage uniformity [58] | Variable coverage across targets [58] |
| Noise & False Positives | Lower noise levels and fewer false positives [58] | Higher potential for amplification artifacts [58] |
Experimental Evidence from Performance Comparisons
Recent systematic evaluations of different bait types used in hybridization capture reveal nuanced performance characteristics across platforms. A comprehensive comparison of four whole-exome capture platforms with different bait types (single-stranded RNA, single-stranded DNA, double-stranded DNA, and double-stranded RNA) demonstrated that platforms with RNA baits cover a greater portion of the exome, while platforms with DNA baits primarily focus on regions of the genome that are easier to capture [61].
Table 2: Performance Metrics of Different Bait Types in Hybridization Capture
| Bait Type | On-target Rate | Uniformity | Capture Efficiency | AT Dropout | Key Strengths |
|---|---|---|---|---|---|
| Single-stranded DNA | 86% (highest) | >95% | 71% (highest) | High (up to 10%) | Highest on-target rate and capture efficiency [61] |
| Double-stranded RNA | 83% | >95% | 69% | Very low | Balanced performance, low AT dropout [61] |
| Single-stranded RNA | Not specified | >95% | Not specified | Very low | Comprehensive exome coverage [61] |
| Double-stranded DNA | Not specified | 99.32% (highest) | Not specified | High | Highest uniformity and complexity [61] |
Notably, each bait type exhibited different biases: DNA baits showed better performance in regions with high GC content, while RNA baits demonstrated lower AT dropout, suggesting that different bait types have distinct binding affinities to genomic regions with different characteristics [61]. The platform with double-stranded RNA baits demonstrated the most balanced capture performance overall [61].
Methodological Frameworks for Performance Benchmarking
Reference Materials and Benchmarking Metrics
The National Institute of Standards and Technology (NIST) has developed reference materials for five human genomes, known as Genome in a Bottle (GIAB), which provide high-confidence truth sets for benchmarking targeted sequencing panels [62]. These reference materials enable standardized performance assessment using metrics such as sensitivity, precision, and false discovery rates across different experimental conditions and bioinformatics pipelines [62].
The Global Alliance for Genomics and Health (GA4GH) has standardized performance metrics and developed sophisticated variant comparison tools that enable robust comparison of different variant representations [62]. These tools calculate performance metrics following standardized definitions, where genotyping errors are counted as both false positives and false negatives, and stratify performance by variant type, size, and genomic context to elucidate methodological strengths and weaknesses [62].
Experimental Protocols for Targeted Sequencing Evaluation
Hybridization Capture Protocol
For hybridization-based target enrichment, library preparation typically involves fragmenting genomic DNA, followed by end-polishing and adapter ligation [62]. Pooled libraries are then hybridized with target-specific probes (e.g., biotinylated oligonucleotides), which are subsequently captured using streptavidin-coated magnetic beads [60]. After washing to remove non-specifically bound DNA, the enriched libraries are amplified and sequenced [62]. For example, in one validated protocol, the TruSight Rapid Capture kit and TruSight Inherited Disease Sequencing Panel were used according to manufacturer specifications, with hybridization performed twice at 58°C with inherited disease panel oligos [62].
Amplicon Sequencing Protocol
Amplicon sequencing employs a fundamentally different approach, using polymerase chain reaction (PCR) to directly amplify regions of interest [60]. In a representative protocol, the Ion AmpliSeq Library Kit 2.0 and AmpliSeq Inherited Disease Panel were used according to manufacturer instructions [62]. DNA from each genome is amplified in separate primer pools, after which these PCR products are combined for barcoding and library preparation [62]. The final library concentration is typically measured using quantification kits specifically designed for library preparation workflows [62].
Integration with Short-read and Long-read Sequencing Platforms
The choice between short-read and long-read sequencing platforms introduces additional considerations for experimental design. Short-read sequencing (e.g., Illumina platforms) provides high-throughput, high-quality information at the gene level, while long-read technologies (e.g., Pacific Biosciences and Oxford Nanopore) offer isoform resolution through full-length transcript sequencing [7].
Recent benchmarking efforts, such as the Singapore Nanopore Expression (SG-NEx) project, have systematically compared multiple RNA-seq protocols across seven human cell lines [6]. This comprehensive resource enables direct performance comparisons between short-read cDNA sequencing, Nanopore long-read direct RNA, amplification-free direct cDNA, PCR-amplified cDNA sequencing, and PacBio IsoSeq [6].
Experimental Workflow Visualization
Targeted Sequencing Method Selection Workflow
Applications and Performance in Real-World Scenarios
Sensitive Pathogen Detection
Hybridization capture has demonstrated remarkable utility in sensitive pathogen detection applications. A recently developed method employing 149,990 probes targeting 663 human and animal viruses achieved substantial improvements over standard metagenomic next-generation sequencing (mNGS), with read enrichment increases ranging from 143- to 1126-fold [59]. This approach enhanced detection sensitivity by lowering the limit of detection from 10³-10⁴ copies to as few as 10 copies based on whole genomes, while also increasing viral genome coverage to >99% in medium-to-high viral loads [59].
Single-Cell RNA Sequencing Considerations
In single-cell RNA sequencing (scRNA-Seq) experimental design, trade-offs exist between the number of cells sequenced, sequencing depth per cell, and the number of samples included in a study [63]. Research has demonstrated that for cell-type-specific expression quantitative trait locus (ct-eQTL) mapping, statistical power can be maximized by sequencing more cells and samples at lower coverage per cell rather than fewer samples at high coverage [63]. This approach leverages the fact that cell-type-specific gene expression can be accurately inferred by aggregating reads across cells within a cell type, even with low per-cell sequencing depth [63].
Optimization Strategies for Targeted Sequencing
Coverage and Uniformity Considerations
The effect of sequencing depth on performance metrics follows a nonlinear relationship, with diminishing returns beyond certain coverage thresholds [62]. Experimental data suggest that uniformity of coverage varies significantly between hybridization capture and amplicon approaches, with implications for variant detection sensitivity across targeted regions [58] [61].
Bioinformatics Pipeline Optimization
The accuracy of targeted sequencing results depends critically on appropriate bioinformatics pipeline configuration. Studies have demonstrated that optimized analytical tool selection and parameter configuration based on specific data characteristics—rather than using default parameters across different species—can provide more accurate biological insights [64]. For example, in fungal RNA-seq data analysis, systematically evaluating 288 analytical pipelines revealed that carefully selected analysis combinations after parameter tuning yielded superior results compared to default configurations [64].
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Research Reagent Solutions for Targeted Sequencing
| Reagent/Material | Function | Example Products |
|---|---|---|
| Reference Materials | Benchmarking and validation of sequencing methods | NIST Genome in a Bottle (GIAB) reference materials [62] |
| Hybridization Capture Probes | Target enrichment through sequence-specific binding | TruSight Inherited Disease Panel [62], Twist Bioscience probes [59] |
| Amplification Primers | Target-specific amplification for amplicon sequencing | Ion AmpliSeq Inherited Disease Panel [62] |
| Library Preparation Kits | Fragment processing, adapter ligation, and library amplification | TruSight Rapid Capture kit [62], Ion AmpliSeq Library Kit 2.0 [62] |
| Target Enrichment Baits | Sequence-specific capture of genomic regions | SureSelect (single-stranded RNA), xGEN (single-stranded DNA), Twist (double-stranded DNA), QuarXeq (double-stranded RNA) [61] |
| Quality Control Assays | Assessment of library quality and quantity | Bioanalyzer High Sensitivity DNA chip [62], Qubit dsDNA HS Assay [62] |
Hybridization capture and amplicon sequencing offer complementary approaches for targeted sequencing, with the optimal choice dependent on specific research requirements. Hybridization capture excels in applications requiring comprehensive variant detection across large genomic regions, while amplicon sequencing provides a streamlined workflow for focused studies of smaller target sets [58]. Recent advances in bait chemistry, particularly double-stranded RNA baits, demonstrate promising improvements in capture performance and balance [61].
When integrated with appropriate sequencing platforms—short-read for high-throughput gene-level analysis or long-read for isoform resolution and structural variant detection—these targeted approaches enable researchers to maximize both value and resolution within budget constraints [63] [6]. As benchmarking resources such as the GIAB reference materials and standardized performance metrics continue to mature [62], researchers are better equipped than ever to select and optimize targeted sequencing strategies that address their specific biological questions while maintaining rigorous quality standards.
Head-to-Head Comparisons: Validating Performance Across Platforms
Comparative Studies on Transcript Recovery and Gene Count Correlation
The transition from short-read to long-read RNA sequencing (RNA-seq) technologies represents a paradigm shift in transcriptome analysis. Short-read RNA-seq, primarily using Illumina platforms, has been the workhorse for gene expression studies for over a decade, offering high throughput and base-level accuracy [4]. However, its fundamental limitation in read length (typically 50-300 bp) prevents the direct sequencing of full-length transcript isoforms, making transcript-level inference challenging [4]. In contrast, long-read RNA-seq technologies from Pacific Biosciences (PacBio) and Oxford Nanopore Technologies (ONT) can sequence complete RNA molecules in a single read, enabling direct observation of transcript isoforms without assembly [6] [4].
This comparison guide objectively evaluates the performance of these competing technologies through the lens of transcript recovery and gene count correlation—two fundamental metrics in transcriptomics. Transcript recovery refers to the ability to detect and reconstruct full-length transcripts, including novel isoforms, while gene count correlation measures the consistency of gene expression estimates between different methods. Understanding these performance characteristics is crucial for researchers designing experiments, particularly in drug development where accurate transcriptome characterization can identify disease-associated isoforms and biomarkers.
Platform Specifications and Characteristics
Table 1: Comparison of RNA Sequencing Technologies
| Feature | Illumina Short-Read | PacBio Long-Read | ONT Long-Read |
|---|---|---|---|
| Read Length | 50-300 bp | Up to 25 kb | Up to 4 Mb |
| Base Accuracy | >99.9% | ~99.9% (HiFi) | 95-99% (R10.4 chemistry) |
| Throughput | 65-3,000 Gb/flow cell | Up to 90 Gb/SMRT cell | Up to 277 Gb/PromethION flow cell |
| Typical Cost/GB | $12-27 | $65-200 | $22-90 |
| Key Strengths | High accuracy, low cost per base | High-fidelity long reads, small variant detection | Direct RNA sequencing, ultra-long reads, RNA modification detection |
| Primary Limitations | Indirect transcript inference, limited isoform resolution | Historically lower throughput, higher cost | Higher error rates require specialized analysis |
Experimental Workflows
The fundamental difference in experimental approaches between short-read and long-read technologies significantly impacts downstream results:
Short-read workflows typically involve RNA fragmentation, cDNA synthesis, adapter ligation, and PCR amplification before sequencing short fragments. The connectivity between distant exons is lost, requiring computational reconstruction of transcript isoforms [4].
Long-read workflows vary by platform:
- PacBio Iso-Seq sequences circularized cDNA molecules multiple times to generate high-fidelity consensus sequences
- ONT direct RNA sequences native RNA molecules without cDNA conversion, enabling detection of RNA modifications
- ONT cDNA protocols include PCR-amplified, amplification-free direct cDNA, and PCR-cDNA approaches with different throughput and accuracy characteristics [6]
Figure 1: Experimental workflows for short-read and long-read RNA-seq technologies demonstrate fundamental differences that impact transcript recovery capabilities. Long-read methods preserve connectivity information lost in short-read approaches.
Performance Benchmarking
Transcript Recovery and Identification
Multiple consortium-led efforts have systematically evaluated the transcript recovery performance of long-read RNA-seq methods. The Long-read RNA-Seq Genome Annotation Assessment Project (LRGASP) Consortium generated over 427 million long-read sequences from human, mouse, and manatee samples using diverse protocols and sequencing platforms [22]. Their key findings revealed that libraries producing longer, more accurate sequences yield more precise transcript identifications compared to those with simply greater read depth, though increased depth improved quantification accuracy [22].
The Singapore Nanopore Expression (SG-NEx) project provided further insights through a comprehensive benchmark of five different RNA-seq protocols across seven human cell lines. This study demonstrated that long-read RNA-seq more robustly identifies major isoforms compared to short-read approaches, with different Nanopore protocols (direct RNA, amplification-free direct cDNA, and PCR-amplified cDNA) showing distinct performance characteristics [6]. Direct RNA sequencing preserved RNA modification information while cDNA-based approaches offered higher throughput.
Table 2: Transcript Recovery Performance Across Platforms
| Performance Metric | Short-Read Illumina | PacBio Iso-Seq | ONT Direct RNA | ONT cDNA |
|---|---|---|---|---|
| Full-length Transcript Detection | Limited (assembly required) | Excellent | Excellent | Excellent |
| Novel Isoform Discovery | Moderate (high ambiguity) | High | High | High |
| Splice Junction Accuracy | Variable (depends on coverage) | High | High | Moderate |
| Single-cell Isoform Resolution | Limited | Good (with MAS-ISO-seq) | Not applicable | Good |
| Effect of Read Depth | Improves gene-level quantification | Improves isoform quantification | Improves isoform quantification | Improves isoform quantification |
Gene Count Correlation Between Platforms
Understanding the correlation of gene expression measurements between platforms is essential for cross-study comparisons and method validation. A particularly informative study directly compared single-cell long-read and short-read sequencing using the same 10x Genomics 3' cDNA libraries, enabling molecule-level matching through cell barcodes and unique molecular identifiers (UMIs) [7].
This rigorous approach revealed that both methods yield highly comparable results and recover a large proportion of cells and transcripts. However, platform-specific cDNA library processing and data analysis introduced distinct biases. Short-read sequencing provided higher sequencing depth, while long-read sequencing retained transcripts shorter than 500 bp and enabled removal of degraded cDNA contaminated by template switching oligos [7]. Filtering of artifacts identifiable only from full-length transcripts reduced gene count correlation between the two methods, highlighting how quality control steps specific to each technology affect final expression estimates.
The LRGASP consortium further identified that in well-annotated genomes, reference-based tools demonstrated superior performance for transcript quantification, though differences in analytical goals led to moderate agreement among bioinformatics tools [22]. This suggests that both the technology and choice of computational methods impact the final gene count results.
Analysis Tools and Methodologies
Computational Tools for Long-Read Data
The evolution of long-read RNA-seq technologies has necessitated development of specialized computational tools. The LRGASP Consortium evaluated 14 computational tools and found that no single method emerged as a clear frontrunner across all applications [22] [4]. Tool performance varied significantly depending on study objectives, with some excelling at quantifying annotated transcript isoforms and others more receptive to discovering novel isoforms.
Notable tools include:
- StringTie2: A reference-guided transcriptome assembler that works with both short and long reads, implementing new methods to handle the higher error rate of long reads [65]
- Bambu: Uses machine learning to identify novel transcripts from long-read data
- IsoQuant: Focuses on accurate transcript identification and quantification
- ESPRESSO: Aggregates information across multiple reads to refine alignments and improve discovery of full-length isoforms
- TranSigner: A recently developed tool that provides read-level support for transcripts using a guided expectation-maximization algorithm to assign reads to transcripts and estimate abundances [66]
Impact of Analysis Methods on Results
The choice of computational methods significantly impacts transcript recovery and quantification results. TranSigner demonstrated superior performance in read assignment accuracy and abundance estimation compared to tools like NanoCount, Oarfish, Bambu, IsoQuant, and FLAIR when evaluated on simulated and experimental data from Homo sapiens, Arabidopsis thaliana, and Mus musculus [66].
Tools specifically designed for long-read data typically outperform those adapted from short-read methodologies. For example, StringTie2 was shown to assemble long reads more accurately, faster, and with less memory than FLAIR, while also capable of identifying novel transcripts without reference annotation [65]. These differences in tool performance directly affect both transcript recovery rates and gene count correlations between studies.
Experimental Design Considerations
Research Reagent Solutions
Table 3: Essential Research Reagents and Platforms for RNA-seq Studies
| Reagent/Platform | Function | Application Context |
|---|---|---|
| 10x Genomics 3' Reagent Kits | Single-cell partitioning and barcoding | Single-cell RNA-seq (compatible with both short and long-read sequencing) |
| PacBio MAS-ISO-seq Kit | Concatenates transcripts for efficient sequencing | Increases throughput of full-length single-cell RNA-seq |
| ONT Direct RNA Sequencing Kit | Sequences native RNA without cDNA conversion | Detection of RNA modifications and natural RNA sequences |
| Spike-in RNA Controls (ERCC, SIRV) | Quality control and normalization | Quantification accuracy assessment across platforms |
| Template Switching Oligo (TSO) | cDNA synthesis efficiency | Artifact identification in single-cell protocols |
| Poly(A) Selection Beads | mRNA enrichment from total RNA | Reduces ribosomal RNA contamination |
Recommendations for Experimental Design
Based on comparative studies, researchers should consider the following when designing transcriptomics studies:
For comprehensive transcriptome annotation: Long-read RNA-seq is superior for discovering full-length transcripts and novel isoforms, with PCR-cDNA protocols providing the highest throughput for identification, and direct RNA or direct cDNA enabling modification detection or reducing amplification bias [6]
For large-scale differential expression studies: Short-read RNA-seq remains cost-effective for gene-level differential expression, while long-read approaches are preferable for isoform-level differential expression
For single-cell analyses: New methods like PacBio's MAS-ISO-seq (now Kinnex) enable cost-effective isoform-resolution single-cell sequencing, though short-read approaches currently provide higher cell throughput [7]
For clinical samples with limited RNA quality: The higher error tolerance of short-read methods may be advantageous for degraded samples, though all platforms show reduced performance with low RNA integrity
For orthogonal validation: Incorporating additional orthogonal data and replicate samples is recommended when aiming to detect rare and novel transcripts or using reference-free approaches [22]
Figure 2: Decision framework for selecting RNA-seq technologies based on research goals, highlighting how different applications warrant distinct technology choices.
Comparative studies on transcript recovery and gene count correlation demonstrate that long-read RNA-seq technologies provide substantial advantages for comprehensive transcriptome characterization, particularly for identifying full-length transcripts and novel isoforms. While short-read approaches remain competitive for gene-level quantification studies due to lower costs and higher throughput, long-read methods enable researchers to explore previously inaccessible dimensions of transcriptome complexity.
The correlation between gene counts derived from different platforms is generally high, though affected by platform-specific biases and analytical approaches. As long-read technologies continue to evolve with improving accuracy and decreasing costs, they are positioned to become the foundational technology for transcriptome analysis, particularly in biomedical research and drug development where complete understanding of isoform diversity is critical.
Researchers should select technologies and analytical methods based on their specific study objectives, considering that transcript discovery benefits from longer, more accurate reads, while quantification accuracy improves with greater sequencing depth. Incorporating spike-in controls, experimental replicates, and orthogonal validation remains essential for robust transcriptome analysis regardless of the platform chosen.
The accurate identification of genetic variants—Single Nucleotide Variants (SNVs), short insertions and deletions (indels), and Structural Variants (SVs)—is a cornerstone of genomic research and precision medicine. Traditionally, this field has been dominated by DNA sequencing approaches. However, within the broader thesis of comparing short-read versus long-read RNA sequencing, a critical paradigm shift is emerging: moving beyond merely cataloging DNA-level variants to understanding their functional transcriptional consequences. RNA sequencing (RNA-seq) uniquely bridges the gap between DNA alteration and cellular phenotype by revealing which variants are actually expressed, how they influence splicing, and whether they exhibit allele-specific expression [67] [68]. This guide provides a comprehensive benchmark of variant calling performance across different sequencing technologies, focusing on the unique insights gained from RNA-seq data.
The fundamental limitation of DNA-centric assays is their inability to distinguish between a silent mutation in the genome and a functionally expressed variant that may drive disease pathogenesis. As one study notes, "DNA may be considered as 'potential' since the critical transformative steps of transcription and translation must occur prior to building cellular components and machinery" [68]. This is particularly crucial in cancer, where a recent study found that up to 18% of somatic SNVs detected by DNA sequencing were not transcribed, suggesting they may be clinically irrelevant [68]. By contrast, variants detected from RNA-seq are inherently expressed and thus more likely to have functional consequences, providing a more direct window into disease mechanisms.
Performance Benchmarking Across Sequencing Platforms and Technologies
Technology Landscape and Key Characteristics
The performance of variant calling is intrinsically linked to the underlying sequencing technology. Short-read sequencing (e.g., Illumina) generates high accuracy but limited-length reads (150-300 bp), which struggle to resolve repetitive regions and large structural variants. Long-read technologies from Pacific Biosciences (PacBio) and Oxford Nanopore Technologies (ONT) produce reads spanning several kilobases to over a megabase, enabling more comprehensive variant detection, particularly in complex genomic regions [69] [70].
Table 1: Key Sequencing Platform Characteristics for Variant Detection
| Feature | Illumina (Short-Read) | PacBio HiFi | Oxford Nanopore (ONT) |
|---|---|---|---|
| Typical Read Length | 150-300 bp | 10-25 kb | 20-100 kb (can exceed 1 Mb) |
| Raw Read Accuracy | >99.9% (Q30+) | >99.9% (Q30-Q40) | ~98-99.5% (Q20+ with recent improvements) |
| Strengths for Variant Calling | High SNV/small indel accuracy; cost-effective | Excellent SV detection and phasing; high consensus accuracy | Ultra-long reads for complex SVs; real-time analysis |
| Limitations for Variant Calling | Poor performance in repeats and for large SVs | Higher cost per sample; shorter reads than ONT | Historically higher error rates requiring specialized callers |
Recent advances have significantly narrowed the performance gap between these technologies. For long-read platforms, improvements in chemistry and basecalling algorithms (e.g., ONT's Q20+ chemistry and Dorado basecaller) have elevated accuracy beyond 99%, enhancing their competitiveness for clinical applications [69].
Benchmarking SNV and Indel Detection
The performance of SNV and indel detection varies significantly between short-read and long-read technologies, particularly for specific variant types and genomic contexts. A comprehensive 2024 evaluation of 21 popular variant detection algorithms using both short- and long-read WGS data revealed critical patterns [71].
Table 2: SNV and Indel Detection Performance Across Technologies
| Variant Type | Short-Read Performance | Long-Read Performance | Key Observations |
|---|---|---|---|
| SNVs | High recall and precision in non-repetitive regions | Comparable performance in non-repetitive regions | Minimal differences between technologies in unique sequences |
| Indel Deletions | Good performance for small deletions | Excellent performance across all size ranges | Short-read performance degrades with increasing size |
| Indel Insertions | Poor detection >10 bp (22% sensitivity for 10-50 bp) | Significantly better detection (74% sensitivity with Sniffles2) | Major advantage for long-read technologies |
| All Indels in Repetitive Regions | Significantly reduced sensitivity | Maintains high sensitivity | Short reads struggle with STRs and segmental duplications |
The particularly poor performance of short-read sequencing for insertions greater than 10 bp represents a critical limitation, as these variants are biologically prevalent and can have significant functional impacts. As the study concludes, "detecting indels, especially insertions, by short read-based algorithms became less sensitive as insertions increased in size, especially in the 10−50 bp range, suggesting that indel calling using short reads needs to cover indels of this size" [71].
Benchmarking Structural Variant Detection
Structural variants (SVs)—genomic alterations ≥50 bp including deletions, duplications, insertions, inversions, and translocations—represent a major source of genetic variation and disease causation but have been historically challenging to detect [70]. Long-read technologies have dramatically improved SV detection capabilities, with one study noting they can increase diagnostic yield by 10-15% in rare disease populations after extensive short-read sequencing fails to provide a diagnosis [69].
Table 3: Structural Variant Calling Performance Comparison
| Technology/Method | Deletion Sensitivity | Insertion Sensitivity | Key Strengths |
|---|---|---|---|
| Illumina Short-Read | 86% (deletions only) | 22% (insertions) | Cost-effective for basic deletion detection |
| Bionano OGM | 95% precision | 95% precision | High precision for validated SVs |
| ONT with Sniffles2 | 90% | 74% | Comprehensive SV profiling |
| PacBio HiFi | F1 scores >95% | F1 scores >95% | Exceptional accuracy for clinical applications |
The performance differences are particularly pronounced in challenging genomic regions. "The recall of SV detection with short-read-based algorithms was significantly lower in repetitive regions, especially for small- to intermediate-sized SVs, than that detected with long-read-based algorithms. In contrast, the recall and precision of SV detection in nonrepetitive regions were similar between short- and long-read data" [71]. This highlights a fundamental limitation of short-read technologies—their inability to resolve variants in repetitive regions, which are known SV hotspots.
Special Considerations for RNA-Seq Based Variant Calling
Unique Advantages of RNA-Seq for Variant Detection
Variant calling from RNA-seq data provides unique advantages that complement DNA-based approaches:
- Functional Validation of Expressed Variants: RNA-seq directly reveals which DNA variants are actually transcribed, providing evidence of their potential functional relevance. In cancer research, this helps distinguish driver mutations from passenger mutations [68].
- Allele-Specific Expression (ASE) Detection: RNA-seq can identify imbalances in the expression of alleles, which may result from cis-regulatory variants or epigenetic modifications. A recent study using PacBio Kinnex data identified "88 significant allele-specific splicing events per sample on average" [13].
- Identification of Fusion Transcripts and Alternative Splicing: RNA-seq is uniquely positioned to detect gene fusions and alternative splicing events resulting from SVs, providing immediate insight into their potential functional consequences [70].
- Enhanced Sensitivity in Highly Expressed Genes: For moderate to highly expressed genes, RNA-seq can provide stronger mutation signals than DNA-seq, particularly in low-purity tumor samples [68].
Methodological Approaches and Tools
Specialized computational methods have been developed to address the unique challenges of RNA-seq variant calling, particularly the high false-positive rates caused by alignment errors near splice junctions, RNA editing sites, and the non-uniform read depth due to variable gene expression.
VarRNA is one such method specifically designed for RNA-seq data that utilizes two XGBoost machine learning models to classify variants as germline, somatic, or artifact directly from tumor transcriptomes without requiring a matched normal sample [67]. This approach demonstrates how machine learning can overcome the limitations of simply applying DNA variant callers to RNA-seq data.
For targeted RNA-seq, which provides deeper coverage of genes of interest, specialized panels like the Afirma Xpression Atlas have been developed for clinical decision-making, demonstrating the translational potential of RNA-based variant detection [68].
Diagram 1: RNA-Seq Variant Calling Workflow. This diagram illustrates the key steps in specialized RNA-seq variant calling pipelines like VarRNA, which includes machine learning classification to distinguish true variants from artifacts and germline from somatic variants.
Experimental Protocols and Methodologies
Standardized DNA Sequencing and Variant Calling Workflow
To ensure reproducible and accurate variant detection, the following standardized protocol is recommended based on methodologies from recent benchmarking studies:
Sample Preparation and Sequencing:
- DNA Extraction: Use high molecular weight DNA extraction protocols, such as the QIAGEN Gentra Puregene Blood Kit, with quality control via pulsed-field capillary electrophoresis (e.g., Agilent FemtoPulse) [72].
- Library Preparation: For Illumina short-read sequencing, follow manufacturer's protocols for 150-300 bp insert libraries. For PacBio HiFi, use SMRTbell library preps with size selection (20-50 kb fragmentation). For ONT, utilize ligation-based kits (e.g., SQK-LSK110) with fragmentation to 20-50 kb [72].
- Sequencing Coverage: Target minimum 30x coverage for both short-read and long-read WGS, with higher coverage (50-60x) recommended for comprehensive SV detection [73] [74].
Computational Analysis:
- Read Alignment: For short reads, use BWA-MEM2 or DRAGMAP aligned to GRCh38. For long reads, use Minimap2 for ONT data or Pbmm2 for PacBio data [73] [74].
- Variant Calling:
- Variant Filtering and Annotation: Apply platform-specific quality filters, then annotate using Ensembl VEP or similar tools.
Diagram 2: Standard DNA Variant Detection Workflow. This generalized workflow shows the key steps from sample collection to variant calling and benchmarking, highlighting stages where technology choice significantly impacts results.
Specialized RNA-Seq Variant Calling Protocol
For variant calling from RNA-seq data, the following specialized protocol is recommended:
Sample Preparation and Sequencing:
- RNA Extraction: Use methods that preserve RNA integrity (RIN > 8) and remove genomic DNA contamination.
- Library Preparation: For short-read RNA-seq, use poly-A selection or ribodepletion protocols. For long-read RNA-seq (Iso-Seq), use PacBio's Kinnex kits or ONT's cDNA sequencing protocols [13].
- Sequencing Depth: Target 50-100 million reads per sample for short-read RNA-seq; for long-read, aim for sufficient coverage to detect isoforms of interest.
Computational Analysis (based on VarRNA workflow):
- Read Alignment: Use STAR two-pass alignment to GRCh38 for short reads, or specialized isoform-aware aligners for long reads [67].
- Post-processing: Include steps for duplicate marking, base quality score recalibration, and splitting reads at splice junctions.
- Variant Calling: Use GATK HaplotypeCaller for initial variant calling with "do-not-use-soft-clipped-bases" parameter enabled [67].
- Variant Filtering and Classification: Apply VarRNA's two-step XGBoost classification to distinguish true variants from artifacts and then classify true variants as germline or somatic [67].
The Scientist's Toolkit: Essential Research Reagents and Computational Solutions
Table 4: Key Research Reagent Solutions for Variant Detection Studies
| Category | Product/Technology | Key Function | Application Notes |
|---|---|---|---|
| DNA Sequencing Kits | Illumina DNA PCR-Free Prep | Short-read WGS library preparation | Minimizes PCR bias for accurate variant calling |
| PacBio SMRTbell Prep Kit | HiFi long-read library preparation | Enables high-fidelity circular consensus sequencing | |
| ONT Ligation Sequencing Kit | Nanopore long-read library preparation | Facilitates ultra-long reads for complex SV detection | |
| RNA Sequencing Kits | Illumina Stranded mRNA Prep | Short-read transcriptome sequencing | Standard for expression quantification and variant detection |
| PacBio Kinnex RNA Single-Cell | Full-length isoform sequencing | Enables isoform-level variant detection and ASE | |
| DNA Extraction | QIAGEN Gentra Puregene Blood Kit | HMW DNA preservation | Critical for long-read sequencing success |
| Targeted Panels | Agilent ClearSeq Comprehensive Cancer | Targeted DNA sequencing | Focused coverage of cancer-related genes |
| Roche Comprehensive Cancer Panel | Targeted DNA/RNA sequencing | Dual-purpose panel for integrated analysis |
The comprehensive benchmarking of variant calling technologies reveals a rapidly evolving landscape where long-read sequencing is increasingly overcoming historical limitations to provide more complete variant detection, particularly for structural variants and indels in repetitive regions. However, short-read technologies maintain advantages in cost-effectiveness and SNV detection in unique genomic regions.
The integration of RNA-seq into variant calling workflows represents a significant advancement, enabling researchers to distinguish functionally relevant expressed variants from silent genomic changes. As one study concludes, "Incorporating RNA-seq into clinical biomarker panels will ultimately advance precision medicine and improve patient outcomes by improving the strength and reliability of somatic mutation findings for clinical diagnosis, prognosis and prediction of therapeutic efficacy" [68].
Future directions in the field include the adoption of telomere-to-telomere reference genomes and pangenome graphs to improve variant calling in previously unresolved regions, the development of more sophisticated machine learning tools for variant classification, and the standardization of hybrid approaches that leverage both short-read and long-read technologies for comprehensive variant profiling [69] [74]. As these technologies continue to mature and costs decline, the integration of multi-modal sequencing data will undoubtedly become the gold standard for variant detection in both research and clinical settings.
Accurately assessing the technical performance of RNA sequencing (RNA-seq) technologies is a foundational step in designing robust transcriptomic studies. For researchers choosing between short-read and long-read platforms, key quantitative metrics—including coverage uniformity, mapping rates, and error profiles—provide critical, data-driven insights into their respective strengths and limitations. While short-read sequencing (e.g., Illumina) is renowned for its high throughput and base-level accuracy, long-read sequencing (e.g., Pacific Biosciences and Oxford Nanopore Technologies) offers the unique advantage of full-length transcript sequencing, resolving isoform complexity at the cost of different error profiles. This guide objectively compares these platforms using recently published experimental data, providing detailed methodologies and standardized metrics to inform researchers and drug development professionals.
Key Performance Metrics Comparison
The following table summarizes core performance metrics for short-read and long-read RNA-seq technologies, based on direct comparative studies.
Table 1: Comparative Technical Performance of Short-Read and Long-Read RNA-seq
| Performance Metric | Short-Read (Illumina) | Long-Read (PacBio) | Long-Read (Nanopore) | Context and Implications |
|---|---|---|---|---|
| Sequencing Accuracy | ~99.99% [75] | High (Recent improvements) [7] | Theoretically ~99% [75] | Short-reads offer superior base-level accuracy for variant calling [75]. |
| Mapping Rate/Quality | Median Phred score: 33.67 (99.96% accuracy) [75] | Highly comparable to short-read for recovered transcripts [7] | Median Phred score: 29.8 (99.89% accuracy) [75] | Both platforms show high mapping accuracy, suitable for confident alignment [7] [75]. |
| Coverage Uniformity | High sequencing depth; can exceed 100X on target [75] | Retains transcripts <500 bp; filters truncated cDNAs [7] | Resolves large, complex structural variants [75] | Long-reads provide uniform coverage across full-length transcripts, revealing structures short-reads miss [7] [75]. |
| Typical Read Depth | High-throughput; >100 million reads per lane common [76] | Improved via concatenation (e.g., Kinnex) [7] | Lower coverage depth (e.g., ~20X in WGS) [75] | Short-reads provide greater depth for quantifying low-abundance transcripts. |
| Error Profile | Low random error rate [75] | Platform-specific artefacts (e.g., TSO contamination) [7] | Higher random error rate; systematic uncertainties [75] | Long-read library prep and analysis can introduce identifiable, filterable biases [7]. |
Detailed Experimental Protocols and Data
Protocol 1: Cross-Platform Comparison from Shared cDNA
A 2025 study directly compared short- and long-read performance by sequencing the same 10x Genomics 3' complementary DNA (cDNA) library from patient-derived organoid cells on both Illumina and PacBio platforms [7].
- Library Preparation: The same full-length cDNA generated using the 10x Genomics Chromium Single Cell 3' Reagent Kits (v3.1 Chemistry Dual Index) was split for two library types [7].
- Illumina Library: cDNA was enzymatically sheared to 200–300 bp, and libraries were prepared with end repair, A-tailing, adapter ligation, and index PCR. Sequencing was performed on an Illumina NovaSeq 6000 for ~300,000 reads per cell [7].
- PacBio MAS-ISO-seq Library: 45 ng of cDNA was used with the MAS-ISO-seq for 10x Genomics kit. A key step involved using a modified PCR primer to incorporate a biotin tag, enabling streptavidin bead-based removal of template switching oligo (TSO) artefacts. cDNA was then segmented and directionally assembled into long concatemers (10–15 kb) for efficient sequencing on the PacBio Sequel IIe [7].
- Key Findings: This protocol revealed that while short-reads provided higher sequencing depth, long-reads enabled retention of short transcripts and removal of truncated cDNA artefacts. The two methods showed high comparability, though platform-specific processing and more stringent bioinformatic filtering in the long-read pipeline impacted gene count correlations [7].
Protocol 2: Whole-Exome/Genome Sequencing in Colorectal Cancer
A 2025 study on colorectal cancer (CRC) samples provided a detailed comparison of Illumina short-read and Nanopore long-read technologies for variant calling [75].
- Sample Preparation: The study utilized CRC samples, including tumor, matched normal, and healthy tissues. Comparisons were made between:
- Illumina Whole-Exome Sequencing: Data from a prior study was re-analyzed [75].
- Nanopore Whole-Genome Sequencing: Was performed on the same samples. To enable a direct comparison, Nanopore data was filtered using the
GRCh38 ILMN Exome 2.0 Plus PanelBED file to create an in-silico "Nanopore exome" dataset [75].
- Data Analysis: The analysis focused on coverage depth, base composition, mapping quality, and mutation profiling in key CRC genes (e.g., KRAS, BRAF, TP53). Mean coverage for Nanopore whole-genome data was significantly lower (e.g., ~21X for CRC samples) than Illumina exome data (>100X). Nucleotide content analysis showed differences in base composition between the two technologies, which may reflect platform-specific biases [75].
Experimental Workflow and Pathway Analysis
The following diagram illustrates the logical workflow for a cross-platform technical performance assessment, integrating the key experimental steps from the cited protocols.
Diagram 1: Cross-platform RNA-seq technical assessment workflow.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 2: Key Reagents and Tools for Technical Performance Assays
| Item | Function in the Workflow | Specific Example |
|---|---|---|
| 10x Genomics Chromium Kit | Generates barcoded single-cell full-length cDNA libraries from cell suspensions. | Chromium Single Cell 3' Reagent Kits (v3.1 Chemistry Dual Index) [7] |
| MAS-ISO-seq Kit | Prepares long-read sequencing libraries from 10x cDNA; removes TSO artefacts and creates concatemers for efficient sequencing. | MAS-ISO-seq for 10x Genomics Single Cell 3' Kit (Pacific Biosciences) [7] |
| External RNA Controls | Spike-in RNA molecules with known concentrations and ratios used to benchmark accuracy, sensitivity, and dynamic range of experiments. | ERCC ExFold RNA Spike-In Mixes (used in erccdashboard analysis) [77] [78] |
| Solid-Phase Reversible Immobilization (SPRI) Beads | Used for post-amplification cDNA cleanup and size selection in library preparation. | Common in both Illumina and PacBio protocols [7] |
| Bioconductor Packages | Open-source software for bioinformatic analysis of sequencing data, including performance metrics. | erccdashboard R package for technical performance assessment [77] [78] |
The choice between short-read and long-read RNA-seq technologies is not a matter of one being universally superior, but rather which platform's technical performance characteristics best address the specific biological question. Short-read platforms excel in applications demanding high base-level accuracy and deep sequencing for quantifying gene expression levels. In contrast, long-read platforms are transformative for studies of transcriptome complexity, including isoform discovery, resolving structural variations, and detecting novel transcripts, despite their different error profiles and typically lower throughput. As the field advances, the integration of spike-in controls and standardized dashboard metrics, as facilitated by tools like the erccdashboard R package, will be crucial for ensuring reproducible, reliable, and interpretable results in both basic research and drug development [77].
In the field of genomics, the choice between short-read and long-read RNA sequencing (RNA-seq) technologies is pivotal, influencing the depth and scope of biological insights researchers can extract from their data. This guide objectively compares the performance of these two approaches through the lens of real-world experimental data, with a particular focus on applications in cancer research.
Technology at a Glance: Short-Read vs. Long-Read Sequencing
The fundamental difference between these technologies lies in read length. Short-read sequencing (e.g., Illumina) generates fragments of 50-300 bases, while long-read sequencing (e.g., Pacific Biosciences (PacBio) and Oxford Nanopore Technologies (ONT)) can sequence thousands to tens of thousands of bases in a single continuous read [17] [4] [1]. This distinction in scale drives differences in their applications, strengths, and limitations.
The table below summarizes the core characteristics of each technology.
Table 1: Core Technology Comparison of Major Sequencing Platforms
| Feature | Illumina Short-Read | PacBio Long-Read | ONT Long-Read |
|---|---|---|---|
| Typical Read Length | 50-300 bp [4] [1] | Up to 25 kb [4] | Up to 4 Mb [4] |
| Base Accuracy | >99.9% [4] | >99.9% (HiFi) [17] [4] | 95-99% (R10.4 chemistry) [4] |
| Primary Strengths | High throughput, low cost per base, high base-level accuracy [1] | High-fidelity long reads, excellent for variant calling and isoform resolution [4] [54] | Ultra-long reads, direct RNA sequencing, detection of base modifications [4] [54] |
| Key Challenges | Inability to resolve repetitive regions, complex structural variants, and full-length transcripts [17] [1] | Historically lower throughput, higher cost per sample [4] | Higher raw read error rate, though this can be mitigated with sufficient coverage [17] [4] |
Experimental Insights from Direct Comparisons
Case Study 1: Single-Cell RNA-seq in Cancer Organoids
A 2025 study directly compared short-read (Illumina) and long-read (PacBio) sequencing by performing both on the same 10x Genomics 3' complementary DNA (cDNA) from patient-derived clear cell renal cell carcinoma (ccRCC) organoids [7].
- Experimental Protocol: The same single-cell full-length cDNA generated using the 10x Genomics Chromium Single Cell 3' Reagent Kits was split for library preparation on both platforms. The Illumina library was prepared by shearing cDNA to 200-300 bp. The PacBio library used the MAS-ISO-seq protocol, which concatenates transcripts into longer fragments for sequencing [7].
- Key Findings on Data Comparability: The study found that both methods were "highly comparable," recovering a large proportion of cells and transcripts. Short-read sequencing provided higher sequencing depth, but long-read sequencing allowed for the retention of transcripts shorter than 500 bp and enabled the removal of artifacts from the library preparation process [7].
- Impact on Gene Expression: A notable finding was that the filtering of sequencing artifacts, which is only possible with full-length long reads, reduced the correlation of gene counts between the two methods. This highlights how platform-specific data processing can influence final gene expression results [7].
Case Study 2: The LRGASP Consortium Benchmark
The Long-read RNA-Seq Genome Annotation Assessment Project (LRGASP) Consortium conducted a large-scale, systematic benchmark to evaluate the effectiveness of long-read approaches for transcriptome analysis [22].
- Experimental Protocol: The consortium generated over 427 million long-read sequences from human, mouse, and manatee samples using a variety of PacBio and ONT protocols. Developers then used these datasets to address key challenges: transcript isoform detection, quantification, and de novo transcript discovery [22].
- Key Findings on Performance:
- Transcript Identification: Libraries with longer, more accurate sequences (e.g., PacBio HiFi) produced more accurate transcript reconstructions than those with increased read depth but lower accuracy [22].
- Transcript Quantification: Greater read depth was found to be more critical for accurate quantification of transcript abundance than read length or accuracy [22].
- Tool Performance: In well-annotated genomes, tools relying on a reference genome performed best. The consortium recommended incorporating orthogonal data and replicate samples for detecting rare and novel transcripts [22].
Table 2: Summary of Key Experimental Findings from Case Studies
| Study | Focus | Key Short-Read Finding | Key Long-Read Finding |
|---|---|---|---|
| ccRCC Organoid (2025) [7] | Single-cell RNA-seq comparability | Higher sequencing depth and UMI recovery per cell. | Identifies and filters artifacts; retains short transcripts; provides isoform resolution. |
| LRGASP Consortium (2024) [22] | Transcript identification & quantification | (Baseline for comparison) | Read accuracy is key for isoform discovery; read depth is key for quantification. |
Application in Cancer Research: The Long-Read Advantage
Long-read RNA-seq is transformative for exploring transcriptome complexity in human diseases like cancer [9] [4]. Its ability to sequence full-length transcripts in a single read unlocks several critical applications:
- Discovery of Novel Isoforms and Fusion Transcripts: Cancer cells often produce unique transcript isoforms and fusion genes. Long-read sequencing allows for the direct discovery and characterization of these events without computational assembly, providing a clear view of the genetic alterations driving tumorigenesis [6] [4] [54].
- Accurate Quantification of Alternative Splicing: Alternative splicing is a hallmark of cancer. Long reads can unambiguously determine the combination of exons in a transcript, enabling precise quantification of splicing changes that may serve as diagnostic biomarkers or therapeutic targets [4].
- Detection of RNA Modifications: A unique capability of Oxford Nanopore's direct RNA sequencing is the ability to detect RNA modifications (e.g., m6A) as part of the sequencing run. These epigenetic marks play a role in regulating gene expression in cancer and can now be studied transcriptome-wide [6] [4].
The Scientist's Toolkit: Essential Reagents and Materials
The following table details key reagents and their functions in a typical single-cell long-read RNA-seq workflow, as used in the cited case studies.
Table 3: Key Research Reagent Solutions for Single-Cell Long-Read RNA-seq
| Item | Function |
|---|---|
| 10x Genomics Chromium Single Cell 3' Kit | Partitions single cells into nanodroplets (GEMs) for barcoding and reverse transcription [7]. |
| Cell Barcoded Gel Beads | Beads containing unique oligonucleotides with cell barcodes and UMIs to tag all cDNA from a single cell [7]. |
| MAS-ISO-seq for 10x Genomics Kit (PacBio) | Prepares long-read libraries from 10x cDNA; includes steps to remove template-switching oligonucleotide (TSO) artifacts and concatenate transcripts [7]. |
| Unique Molecular Identifiers (UMIs) | Short random sequences that tag each original mRNA molecule, allowing for accurate digital counting and removal of PCR duplicates [7] [79]. |
| Poly-A Capture Oligos | Oligonucleotides that selectively target and capture polyadenylated mRNA molecules from total RNA [7]. |
Experimental Workflow Visualization
The diagram below illustrates a typical integrated workflow for a comparative sequencing study, as performed in the ccRCC organoid case study.
Integrated Workflow for Sequencing Comparison
The following diagram outlines the core data analysis steps following sequencing, leading to the key biological insights relevant to cancer research.
Data Analysis Path to Biological Insights
The choice between short-read and long-read RNA sequencing is not a matter of one being universally superior to the other. Rather, it is driven by the specific research question. Short-read sequencing remains a powerful, cost-effective tool for high-throughput gene expression profiling. However, as the presented case studies demonstrate, long-read sequencing provides an unparalleled ability to discover and quantify full-length transcript isoforms, resolve complex genomic regions, and detect epigenetic modifications. In cancer research, where transcriptomic complexity is a fundamental feature of the disease, long-read technologies are proving to be an indispensable tool for uncovering the molecular mechanisms that drive patient pathology.
Conclusion
Short-read and long-read RNA-seq are powerful, complementary technologies that, when selected appropriately, can profoundly advance transcriptomic research. Short-reads remain the gold standard for cost-effective, high-throughput gene expression quantification, while long-reads are transformative for unraveling transcriptomic complexity, including isoform diversity, structural variations, and RNA modifications. The choice between them is not a matter of superiority but of strategic alignment with research objectives. Future directions point towards more integrated hybrid approaches, continued improvements in long-read accuracy and affordability, and the growing application of these technologies in clinical diagnostics and personalized medicine, ultimately enabling a more complete understanding of disease mechanisms and therapeutic targets.
References
- 1. Short-read sequencing — Knowledge Hub [https://www.genomicseducation.hee.nhs.uk/genotes/knowledge-hub/short-read-sequencing/]
- 2. What is the Difference Between Short and Long-read RNA- ... [https://www.cd-genomics.com/resource-short-and-long-read-rna-seq.html]
- 3. 2 Powerful Tools - Long Read Sequencing and Short Read Seq [https://sampled.com/short-read-sequencing-vs-long-read-sequencing/]
- 4. Long-read RNA sequencing: A transformative technology ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11897757/]
- 5. Long-read sequencing — Knowledge Hub [https://www.genomicseducation.hee.nhs.uk/genotes/knowledge-hub/long-read-sequencing/]
- 6. A systematic benchmark of Nanopore long-read RNA ... [https://www.nature.com/articles/s41592-025-02623-4]
- 7. Comparison of single-cell long-read and short ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12231600/]
- 8. Illumina, PacBio or Oxford Nanopore: Which One to Choose? [https://www.accurascience.com/blogs_3_0.html]
- 9. Long-read RNA sequencing: A transformative technology ... [https://www.sciencedirect.com/science/article/pii/S1525001624007524]
- 10. Sequencing Read Length | How to calculate NGS ... [https://www.illumina.com/science/technology/next-generation-sequencing/plan-experiments/read-length.html]
- 11. HiFi Reads - Highly accurate long-read sequencing [https://www.pacb.com/technology/hifi-sequencing/]
- 12. Nanopore sequencing accuracy [https://nanoporetech.com/platform/accuracy]
- 13. Powered by PacBio: Selected publications from June 2025 [https://www.pacb.com/blog/powered-by-pacbio-selected-publications-from-june-2025/]
- 14. Science unlocked: publication picks from May 2025 [https://nanoporetech.com/blog/science-unlocked-publication-picks-from-may-2025]
- 15. Frontiers | Comparative evaluation of sequencing platforms: Pacific Biosciences, Oxford Nanopore Technologies, and Illumina for 16S rRNA-based soil microbiome profiling [https://www.frontiersin.org/journals/microbiology/articles/10.3389/fmicb.2025.1633360/full]
- 16. Sequencing Read Length:Everything You Need to Know [https://www.cd-genomics.com/blog/sequencing-read-length-comprehensive/]
- 17. Long-read sequencing vs short-read sequencing [https://frontlinegenomics.com/long-read-sequencing-vs-short-read-sequencing/]
- 18. Optimizing Budget and Resolution: Cost-Benefit Analysis ... [https://www.admerahealth.com/blog/optimizing-budget-and-resolution-costbenefit-analysis-of-short-vs-long-reads]
- 19. Evaluation of Long-Read RNA Sequencing Procedures for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12469794/]
- 20. Budgeting for an mRNA-seq project? How much does RNA ... [https://alitheagenomics.com/blog/budgeting-for-an-mrna-seq-project-here-are-the-main-cost-drivers-to-keep-an-eye-on]
- 21. Opportunities and challenges in long-read sequencing data ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-020-1935-5]
- 22. Systematic assessment of long-read RNA-seq methods for ... [https://www.nature.com/articles/s41592-024-02298-3]
- 23. Comparing long-read sequencing technologies [https://www.pacb.com/blog/sequencing-101-comparing-long-read-sequencing-technologies/]
- 24. Measuring differential gene expression by short read ... [https://bmcgenomics.biomedcentral.com/articles/10.1186/1471-2164-10-221]
- 25. Long-read sequencing reveals the RNA isoform repertoire of ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-025-03724-1]
- 26. High Throughput Gene Expression Screening [https://www.genewiz.com/public/services/next-generation-sequencing/high-throughput-gene-expression-screening]
- 27. The Role of Long-Reads in Transcript Isoform Discovery ... [https://www.admerahealth.com/blog/the-role-of-long-reads-in-transcript-isoform-discovery-and-rna-analysis]
- 28. Accurate isoform discovery with IsoQuant using long reads [https://www.nature.com/articles/s41587-022-01565-y]
- 29. LIQA: long-read isoform quantification and analysis - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC8212471/]
- 30. Structural Variants: Mechanisms, Mapping, and Interpretation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12385565/]
- 31. RepeatProfiler: a pipeline for visualization and comparative ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7954937/]
- 32. Comparative evaluation of SNVs, indels, and structural ... [https://www.nature.com/articles/s41439-024-00276-x]
- 33. Sequencing 101: Structural variation [https://www.pacb.com/blog/structural-variation/]
- 34. Comparison of structural variant callers for massive whole ... [https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-024-10239-9]
- 35. A comparison of software for analysis of rare and common ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0300545]
- 36. Complex de novo structural variants are an underestimated ... [https://www.nature.com/articles/s41467-025-64722-2]
- 37. Regular article FindDNAFusion: An Analytical Pipeline with ... [https://www.sciencedirect.com/science/article/pii/S1525157823002751]
- 38. Performance comparison of high throughput single-cell ... [https://www.sciencedirect.com/science/article/pii/S2405844024132161]
- 39. Evaluation of Nanopore direct RNA sequencing updates for ... [https://pubmed.ncbi.nlm.nih.gov/40654629/]
- 40. Uncovering the Epitranscriptome: A Review on mRNA ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12385769/]
- 41. Epitranscriptomic advances in normal and malignant ... [https://www.nature.com/articles/s41375-025-02765-6]
- 42. Whole Transcriptome vs. Targeted Gene Expression Profiling [https://missionbio.com/company/blog/comparison-whole-transcriptome-vs-targeted-gene-expression-profiling/]
- 43. Artifacts and biases of the reverse transcription reaction in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10275267/]
- 44. The impact of PCR duplication on RNAseq data generated ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-025-03613-7]
- 45. Template-switching artifacts resemble alternative ... [https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-019-6199-7]
- 46. Bias in RNA-seq Library Preparation: Current Challenges ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8079181/]
- 47. Long-read sequencing—Pitfalls, benefits and success stories [https://pmc.ncbi.nlm.nih.gov/articles/PMC9845275/]
- 48. Correcting PCR amplification errors in unique molecular ... [https://www.nature.com/articles/s41592-024-02168-y]
- 49. RNA Sequencing Library Preparation [https://www.rna-seqblog.com/rna-sequencing-library-preparation/]
- 50. - Short . Read - vs Sequencing: Choosing the Right... Long Read [https://www.linkedin.com/pulse/short-read-vs-long-read-sequencing-choosing-right-medabio-af7df]
- 51. 5 Best Practices for NGS Library Prep Success [https://dispendix.com/blog/5-best-practices-for-ngs-library-prep-success]
- 52. Considerations for RNA Seq read length and coverage [https://knowledge.illumina.com/library-preparation/rna-library-prep/library-preparation-rna-library-prep-reference_material-list/000001243]
- 53. Integrating short-read and long-read single-cell RNA ... [https://pubmed.ncbi.nlm.nih.gov/40050124/]
- 54. Benefits and Applications of Long-Read Sequencing [https://geneviatechnologies.com/blog/benefits-and-applications-of-long-read-sequencing/]
- 55. A systematic benchmark of Nanopore long-read RNA ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11978509/]
- 56. Evaluation and comparison of computational tools for RNA ... [https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-017-4002-1]
- 57. Top 10 Bioinformatics Tools for scRNA-seq in 2025 [https://neovarsity.org/blogs/top-bioinformatics-tools-for-scrna-seq]
- 58. Hybridization capture vs amplicon sequencing | IDT [https://www.idtdna.com/page/support-and-education/decoded-plus/targeted-sequencing-hybridization-capture-or-amplicon-sequencing/]
- 59. Hybrid Capture-Based Sequencing Enables Highly ... [https://www.mdpi.com/2076-0817/14/3/264]
- 60. Hybridization-Based Target Enrichment for NGS [https://sequencing.roche.com/global/en/article-listing/hybridization-based-target-enrichment.html]
- 61. Performance comparison of four types of target enrichment ... [https://hereditasjournal.biomedcentral.com/articles/10.1186/s41065-021-00171-3]
- 62. Determining Performance Metrics for Targeted Next ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6172655/]
- 63. Optimized design of single-cell RNA sequencing ... [https://www.nature.com/articles/s41467-020-19365-w]
- 64. A comprehensive workflow for optimizing RNA-seq data analysis [https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-024-10414-y]
- 65. Transcriptome assembly from long-read RNA-seq alignments with StringTie2 | Genome Biology | Full Text [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-019-1910-1]
- 66. Enhancing transcriptome expression quantification through ... [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-025-03723-2]
- 67. Variant calling from RNA-Seq data reveals allele-specific ... [https://www.nature.com/articles/s43856-025-00901-y]
- 68. Augmenting precision medicine via targeted RNA-Seq ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12166063/]
- 69. Long-Read Sequencing and Structural Variant Detection [https://pmc.ncbi.nlm.nih.gov/articles/PMC12293859/]
- 70. Structural variant calling: the long and the short of it [https://genomebiology.biomedcentral.com/articles/10.1186/s13059-019-1828-7]
- 71. Comparative evaluation of SNVs, indels, and structural ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11024196/]
- 72. A Comparison of Structural Variant Calling from Short- ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11276380/]
- 73. Benchmarking long-read aligners and SV callers for ... [https://www.nature.com/articles/s41598-024-56604-2]
- 74. A Hitchhiker Guide to Structural Variant Calling [https://www.mdpi.com/2227-9059/13/8/1949]
- 75. Methodological Comparison of Short-Read and Long ... [https://www.mdpi.com/1422-0067/26/18/9254]
- 76. RNA-seq: An assessment of technical reproducibility and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC2527709/]
- 77. Assessing technical performance in differential gene ... [https://www.nature.com/articles/ncomms6125]
- 78. Assessing technical performance in differential gene ... [https://www.rna-seqblog.com/assessing-technical-performance-in-differential-gene-expression-experiments-with-external-spike-in-rna-control-ratio-mixtures/]
- 79. Total RNA Sequencing Breakthroughs Transform ... [https://broadclinicallabs.org/total-rna-sequencing-breakthroughs-transform-research-accessibility/]