Research Articles
Beyond the Blur: Advanced Strategies to Overcome Overplotting in Large-Scale Gene Expression Heatmaps
Large-scale gene expression heatmaps are powerful for visualizing complex biological data but often suffer from overplotting, where dense data points obscure critical patterns.
Beyond the Rainbow: A Scientist's Guide to Optimizing Heatmap Color Scales for Log2 Fold Change Data
This article provides a comprehensive guide for researchers and scientists on optimizing heatmap color scales for visualizing log2 fold change data.
From Data to Discovery: A Comprehensive Guide to Integrating Heatmap Visualization in Your RNA-seq Workflow
This guide provides researchers, scientists, and drug development professionals with a comprehensive framework for effectively integrating heatmap visualizations into RNA-seq data analysis.
A Practical Guide to Handling Outliers in Gene Expression Heatmaps: From Detection to Biological Insight
This article provides a comprehensive framework for researchers and bioinformaticians to manage outliers in gene expression heatmaps.
A Researcher's Guide to Heatmap Sample Annotations: From Basic Labeling to Advanced Biomedical Data Visualization
This article provides a comprehensive guide for researchers and drug development professionals on implementing sample annotations in heatmaps.
How to Select Genes for a Differential Expression Heatmap: A Strategic Guide for Biomedical Researchers
This article provides a comprehensive guide for researchers and drug development professionals on strategically selecting genes for differential expression heatmaps, a critical step in transcriptomic data analysis.
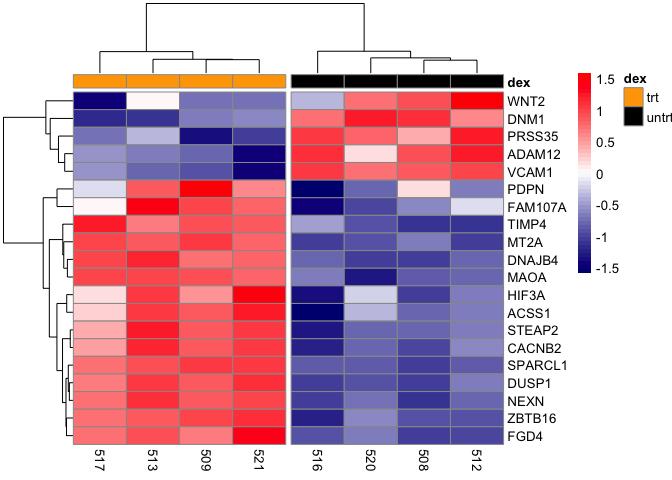
Creating Interactive Gene Expression Heatmaps with heatmaply: A Complete Guide for Biomedical Researchers
This comprehensive guide provides researchers, scientists, and drug development professionals with both theoretical foundations and practical implementation strategies for creating interactive gene expression heatmaps using the R package heatmaply.
A Comprehensive Step-by-Step Guide to Creating Publication-Ready Heatmaps with pheatmap in R
This guide provides researchers, scientists, and drug development professionals with a complete workflow for creating and customizing clustered heatmaps in R using the pheatmap package.
Mastering Data Scaling for Biomedical Heatmaps: A Essential Guide for Accurate Visualization and Interpretation
This article provides a comprehensive guide to data scaling, a critical preprocessing step for generating meaningful and accurate heatmaps in biomedical research.
Heatmaps in Gene Expression Analysis: A Comprehensive Guide from Exploration to Clinical Validation
This article provides a comprehensive overview of the critical role heatmaps play in exploratory gene expression analysis for researchers, scientists, and drug development professionals.